4 Datatyper og datafordelinger
Ift statistisk prosesskontroll er det formålstjenlig å snakke om tre hovedtyper data: måledata, telledata og sjeldne hendelser. Måledata er kontinuerlige data – det vil si de kan måles på en skala som høyde, vekt og tid. Her kan en observasjon/et datapunkt innta en hvilken som helst verdi innenfor et gitt spenn. Høyden på en person kan være 178,34227809 cm eller 178,34227808 cm.
Telledata et kategoriske (også ofte omtalt som diskrete) data – det vil si et datapunkt (en observasjon) kan puttes inn i en klar kategori, som f.eks. antall avvik, antall hendelser, ja/nei, terningkast. Diskrete data har et begrenset antall mulige verdier som er gjensidig utelukkende. Et terningkast med en vanlig terning kan ikke både være 3 og 4 samtidig, en lysbryter kan ikke være av og på samtidig. Et terningkast kan heller ikke være 1,43. Med tanke på datafordeling er både binomial-, Poissonfordeling og geomterisk fordeling diskrete fordelinger, mens normalfordeling og eksponensiell fordeling vil være kontinuerlig (se f.eks. Ugarte, Militino, and Arnholt (2016)).
Når det gjelder sjeldne hendelser kan de være både telledata og måledata. For eksempel vil antall dager mellom en hendelse være en diskret data, mens tid kan måles og vil være kontinuerlige data. Det er spesielle utfordringer med det vi kaller sjeldne hendelser finnes det også egne måter å håndtere dette på i statistisk prosesskontroll, noe vi vil komme tilbake til. For sjeldne henselser vil både geometrisk og eksponensiell fordeling være relevant. Det finnes en god del flere fordelinger enn disse som nå er nevnt, men som Benneyan (1998a) viser er normal-, binomial- og Poissonfordeling de tre vesentligste. For en god oversikt over flere fordelinger, se f.eks. Mun (2008).
Hvorfor fokus på fordelinger?
Fordelingene – normalfordeling, binomialfordeling, Poissionfordeling, geometrisk fordeling og eksponensiell fordeling – beskriver ulike fordelinger ut fra hvordan dataene ser ut. Vi bruker forventningene/sannsynlighetene for ulike verdier i statistisk prosesskontroll til å vurdere om en verdi av en observasjon eller måling er innenfor eller utenfor det vi vil kalle normal variasjon (jfr kapittelet om variasjon). Siden dataene kan være av ulik type – diskret eller kontinuerlig, binomial/ikke binomial osv – bruker vi ulike utregningsmetoder og diagrammer i statistisk prosesskontroll for å få et riktig resultat. Det finnes et antall ulike diagrammer å velge mellom i statistisk prosesskontroll. For å gjøre valget sikrere og lettere kan man bruke følgende flytskjema for å orientere seg.
Siden lesbarheten er litt dårlig for flytskjemaet under kan følgende også brukes: Download Flytdiagram_valg.html
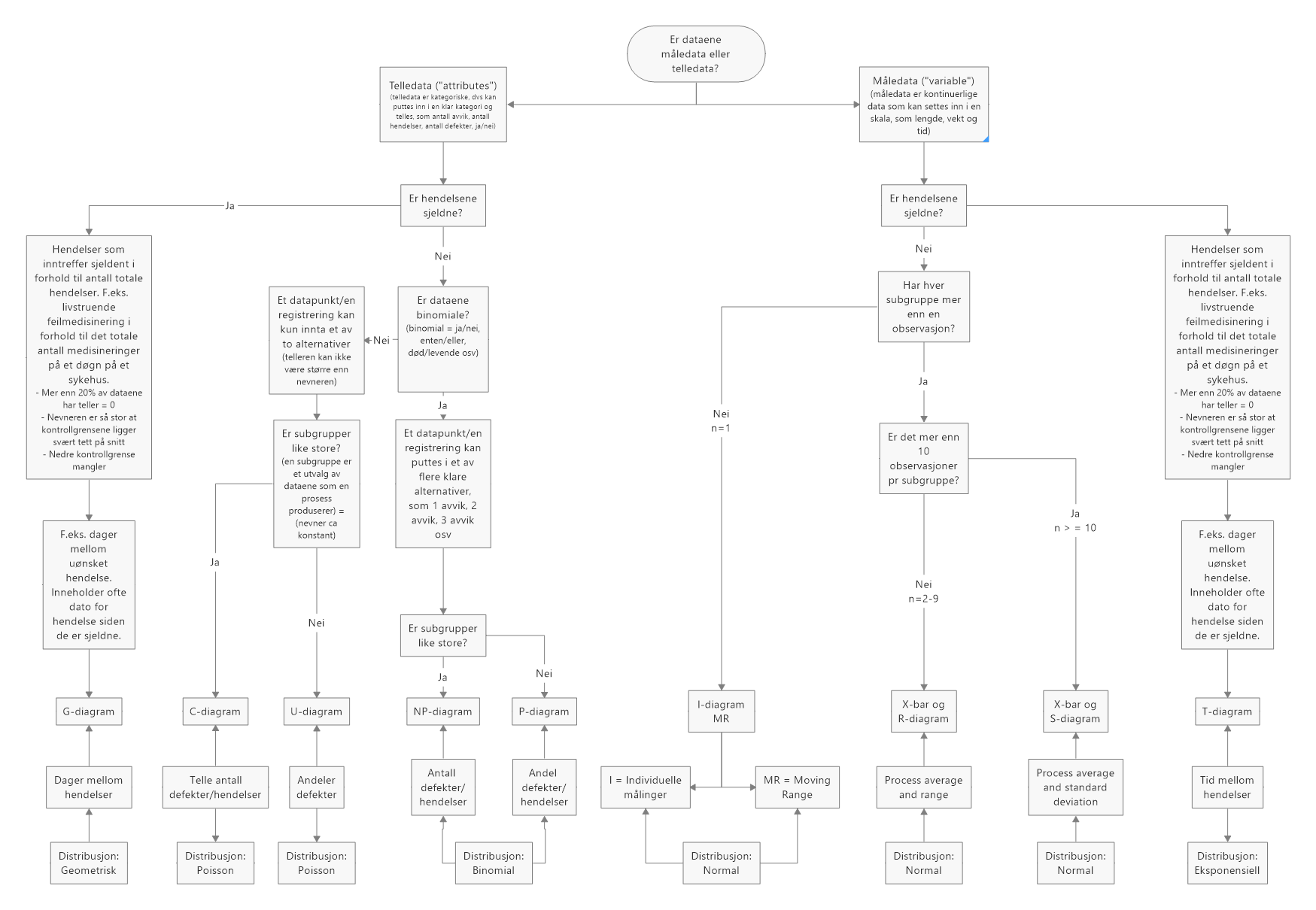
Flytdiagram for valg av analyse
Senere kommer vi tilbake til de ulike diagrammene gjennom praktiske eksempler. Før vi kommer dit vil vi gå gjennom de sentrale datafordelingstypene.
4.1 Normalfordeling
Når vi snakker om distribusjonen av et datasett tenker vi på hvordan dataene vi har samlet inn fordeler seg i forhold til hverandre etter gitte egenskaper. Vi kan for eksempel ha målt høyden på 100 mennesker. Disse dataene utgjør da en observert fordeling som vi kan sette inn i et diagram for å visualisere hvordan datasettet ser ut.
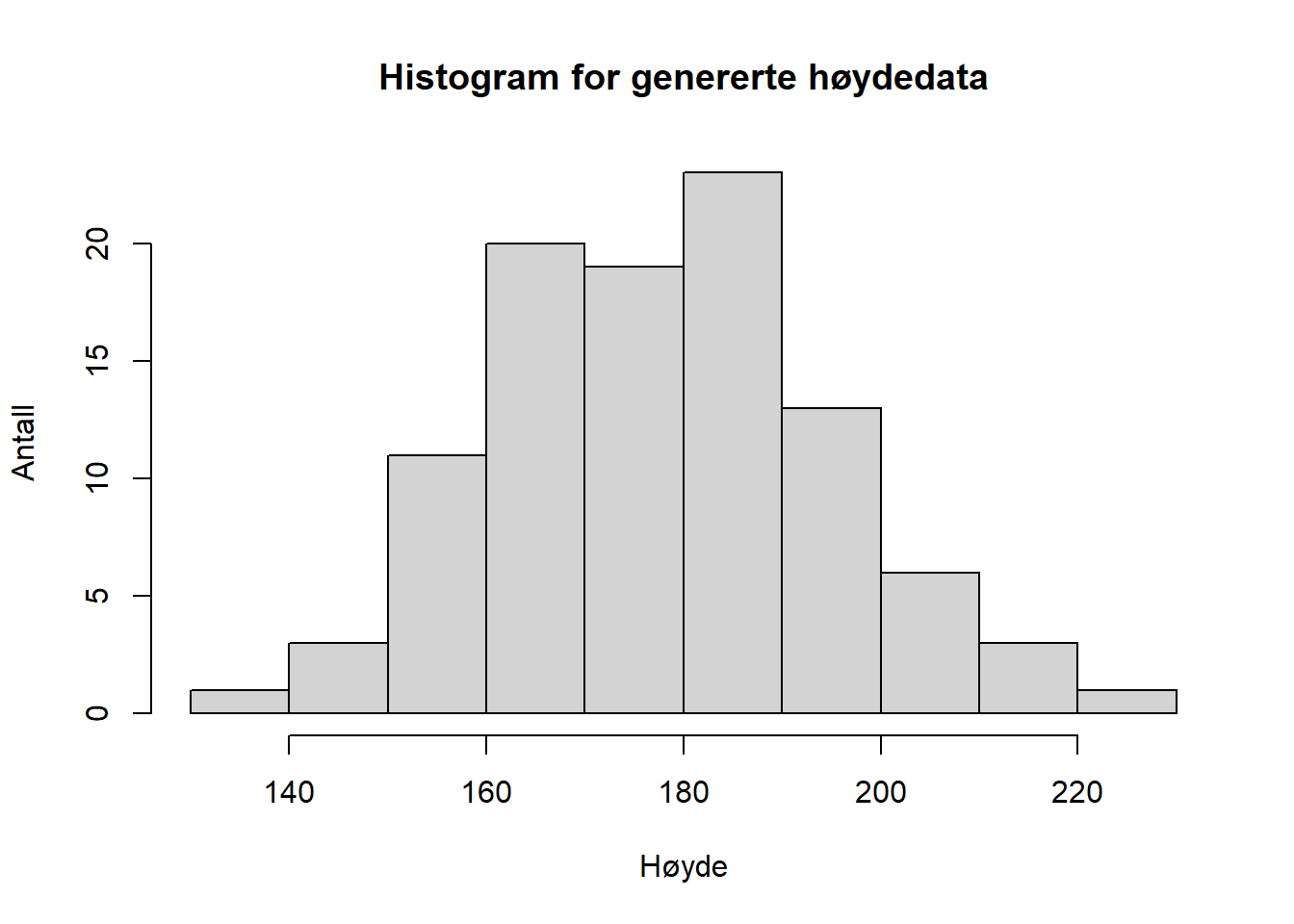
Figure 4.1: Høydefordeling for 100 tilfeldige menn, genererte data
Hvis vi samler inn høydedata for 100 andre tilfeldig menn kan fordelingen se slik ut:
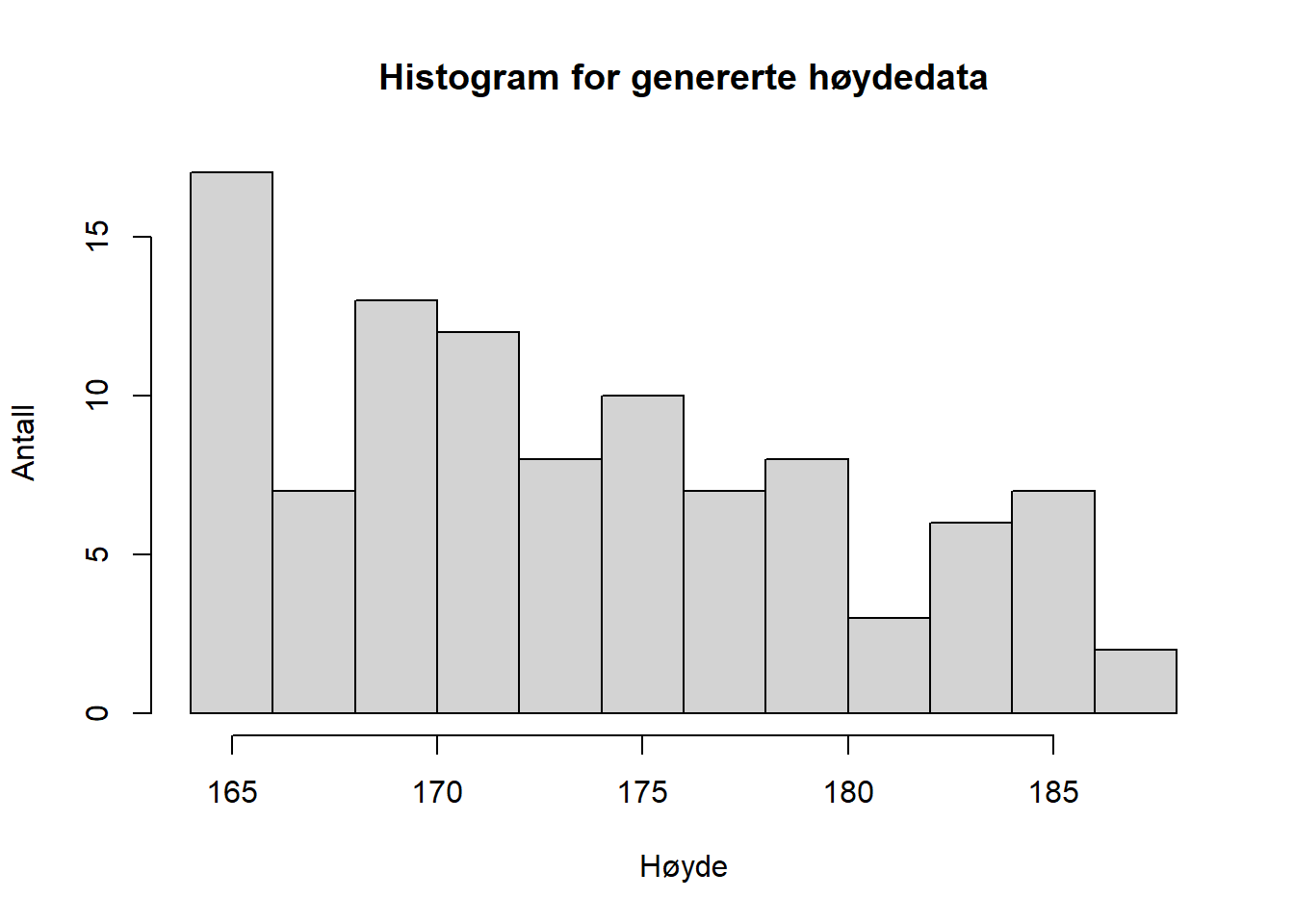
Figure 4.2: Høydefordeling for 100 andre tilfeldige menn, genererte data
Hver gang vi måler høyden på 100 tilfeldig utvalgte menn vil fordelingen se ulik ut siden de er observerte fordelinger i et utvalg av populasjonen (alle) «norske menn». Hvis vi imidlertid økte antallet i utvalget vi målte til 1000 eller 10000 vil vi med større sikkerhet kunne si at vi faktisk viser populasjonens fordeling (mulighetene for at vi tilfeldigvis måler 10000 veldig lave eller veldig høye menn er svært liten). Vi kan derfor, gitt visse forutsetninger om utvalget, si noe om hele populasjonen ut fra utvalget.
Hittil har vi snakket om observerte fordelinger. Ut fra dette kan vi si at vi kan ha visse forventninger til hvordan fordelingen av ulike populasjoner vil se ut, og vi kan snakke om teoretiske fordelinger – eller sannsynlighetsfordelinger med andre ord. Hvor sannsynlig er det at en tilfeldig x-verdi dukker opp i dataene? For høyde kan vi ha visse forventninger til hvilke sannsynligheter det er for at en tilfeldig person har en gitt høyde, eller hvor mange prosent av den mannlige befolkningen som har en høyde innenfor et gitt intervall. Det vil si at fordelingen har en viss form med visse karakteristika. Vi forventer at flest observasjoner befinner seg i nærheten av gjennomsnittet, og at vi vil se færre og færre observasjoner jo lenger unna gjennomsnittet vi beveger oss. Vi forventer å finne flere norske menn over 20 år på rundt 180 cm enn 160 cm eller 210 cm. For fordelingen av høydedata vil vi si at dette er data som er normalfordelte.
En normalfordeling er en sannsynlighetsfunksjon der flesteparten av verdiene fra funksjonen samler seg om en sentral tendens, og der tettheten (hyppigheten) av verdier avtar jevnt jo lenger unna den sentrale tendensen man kommer. Grafisk framstilt får fordelingskurven en klokkeform, og normalfordeling omtales også som “bell shaped”. Overraskende mange fenomener viser seg å være nærme en normalfordeling, og den er derfor en helt sentral teoretisk sannsynlighetsfordeling i mange sammenhenger (også i statistisk prosesskontroll som vi kommer tilbake til senere). Vi bruker dermed normalfordelingen som en modell for observerte data. I en såkalt standard normalfordeling har vi en symmetrisk fordeling der den sentrale tendensen (forventingen) verdi = 0 og et standardavvik = 1.
Vi skal her ikke bry oss om det matematisk uttrykket for sannsynlighetstetthetsfunksjonen. Hvis vi derimot genererer et tenkt datasett etter standard normalfordelingsfunksjon vil det kunne se slik ut:
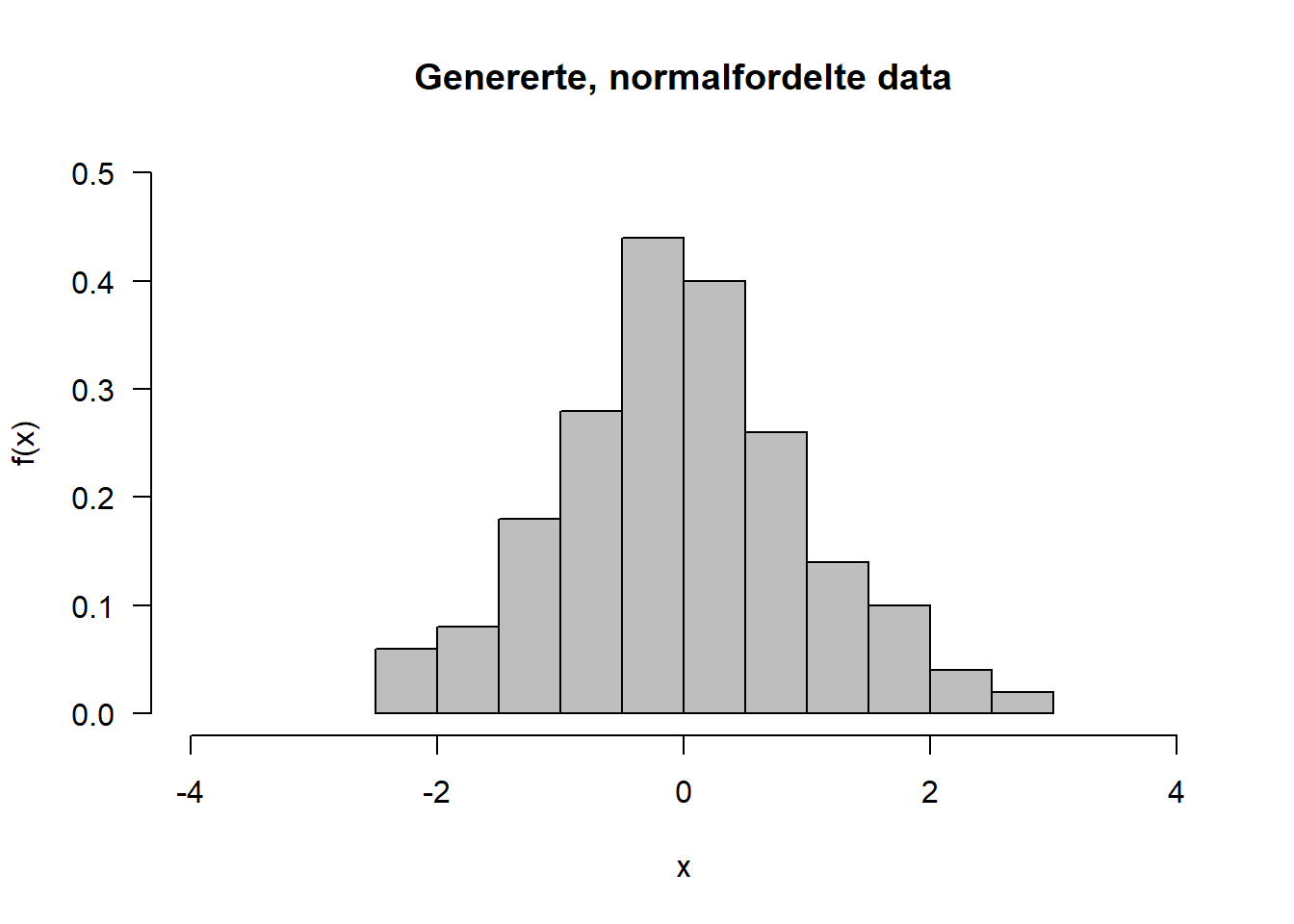
Figure 4.3: Genererte standard normalfordelte data
Her kan vi legge på en forventningskurve – en teoretisk kurve som viser en standard normalfordeling:
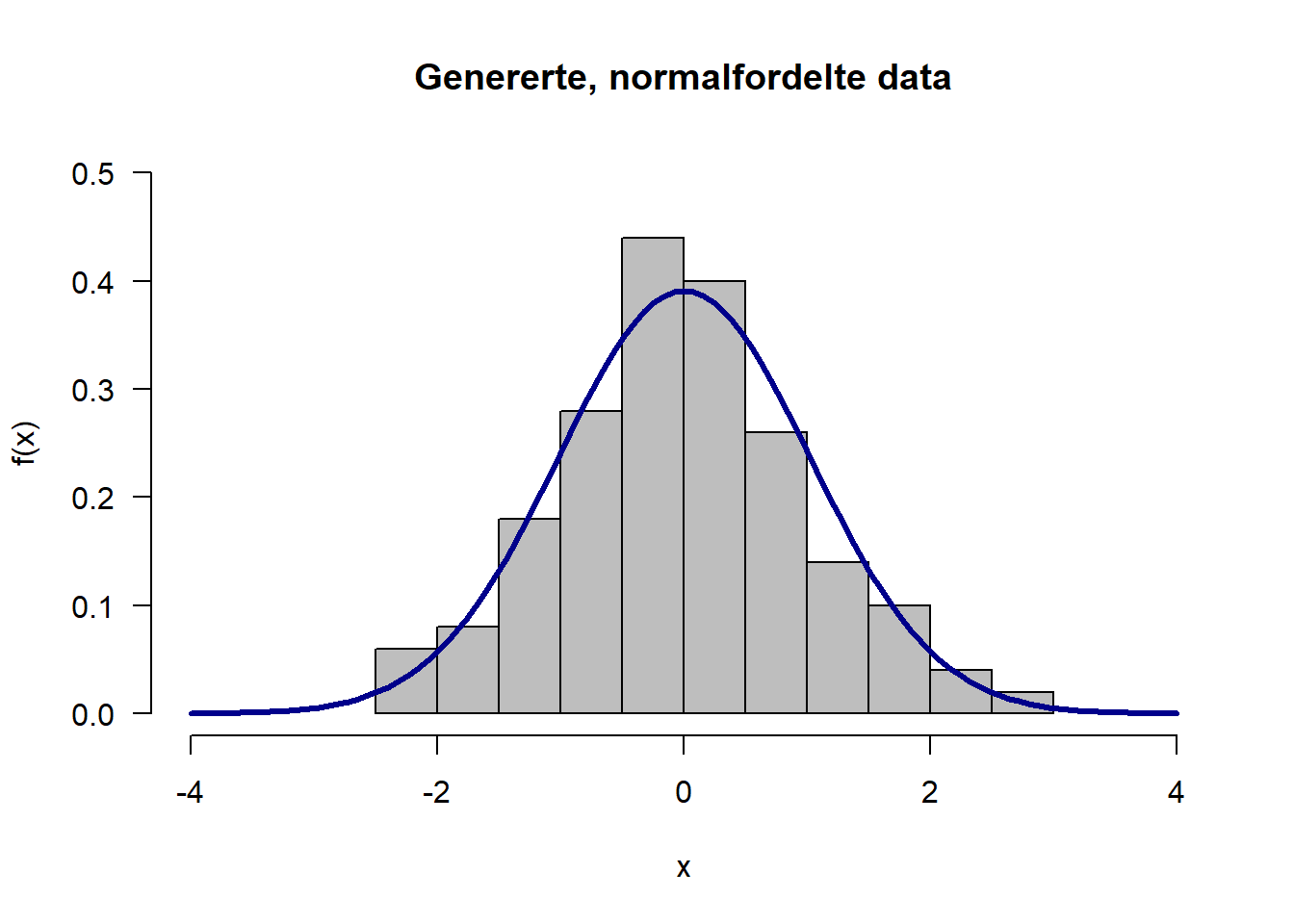
Figure 4.4: Genererte standard normalfordelte data med normalfordelingskurve
Vi kan ta bort det genererte datasettet og sitte igjen med bare normalfordelingskurven:
Figure 4.5: Normalfordelingskurve
Det den standardiserte normalfordelingskurven (også kjent som Gausskurven eller også Bellkurven – “Klokkekurven” fordi den har en klokkeform) – kan brukes til er å si noe om spredningen på forventede verdier – eller hvor langt fra gjennomsnittsverdien man kan forvente å finne de enkelte verdiene.
Før vi ser nærmere på egenskaper ved normalfordelingskurven kan det være nødvendig å gå litt inn på begrepene varians og standardavvik som mål på spredningen i datasett. Disse begrepene, spesielt standardavvik, vil være helt sentrale i videre arbeid med temaet.
4.1.1 Varians og standardavvik
Variansen i en variabel representerer det gjennomsnittlige avviket fra gjennomsnittsverdien (Field, Miles, and Field 2012) og er et mål på spredningen i dataene (som navnet antyder: hvor mye dataene variere ut fra den sentrale tendensen). Under vises et eksempel basert på Field (2009).
La oss anta at vi har spurt 5 studenter på høgskolen hvor mange kjæledyr de har. Svarene kan settes opp i en enkel tabell. I gjennomsnitt har de 2,6 kjæledyr. Vi ønsker imidlertid å se hvor mye avviket er for den enkelte fra snittet (siden vi har regnet ut snittet kan vi se på gjennomsnittsverdien som en modell på forholdet mellom studenter og antall kjæledyr). Vi registrerer svarene vi fikk i et skjema:
Studentnr | Antall | Avvik | Avvik_kvadrert |
1 | 1 | -1.6 | 2.56 |
2 | 2 | -0.6 | 0.36 |
3 | 3 | 0.4 | 0.16 |
4 | 3 | 0.4 | 0.16 |
5 | 4 | 1.4 | 1.96 |
Snitt | 2.6 | ||
Sum | 0 | 5.20 |
Når vi regner ut avviket (sum of deviances) summerer vi avvikene. Siden denne er 0 skulle det innebære at det totalt sett i “modellen” ikke er avvik mellom modellen og våre virkelige observasjoner. Problemet her er at det er både positive og negative avvik som nuller hverandre ut. Man må derfor kvadrere avvikene for å omgå problemet med fortegn. Imidlertid får vi et nytt problem. La oss anta at vi i stedet for 5 studenter har spurt 500. Da får vi et svært høyt kvadrert avvik fra snitt. Altså – vi må ta høyde for for antallet observasjoner. Vi deler derfor sum kvadrert avvik fra snitt på antall observasjoner (5,20/5). MEN: vi må foreta et litt teknisk og komplisert tillegg i utregningen. Vi må dele på antall observasjoner MINUS 1 (som er antallet frihetsgrader – degrees of freedom). Dette vil ikke bli nærmere forklart her, men for de som ønsker å lese mer om frihetsgrader kan prøve noen andre kilder, f.eks. Walker (1940), Good (1973) eller Pandey and Bright (2008). Vi ender altså opp med regnestykket 5,20/(5-1) = 1,3. Dette er variansen. Variansen er altså det gjennomsnittlige avviket mellom gjennomsnittsverdien av de observerte dataene og verdiene til de enkelte observasjonene.
Som regel snakker vi imidlertid om standardavviket. Dette finner vi ved å ta kvadratroten av variansen (som vi jo har funnet ved å kvadrere avvikene for å unngå fortegnsproblemer). Vi får da i vårt tilfelle et standardavvik på 1,14. Variansen og standardavviket forteller oss altså noe om spredningen i dataene. Liten varians betyr at spredningen er liten (om vi har gjennomført en spørreundersøkelse betyr det at respondentene har svart ganske likt). Stor varians betyr stor spredning (respondentene har svart ganske ulikt).
4.1.2 Normalfordeling, standardavvik og forventninger
Vi kan nå se nærmere på normalfordelingen.
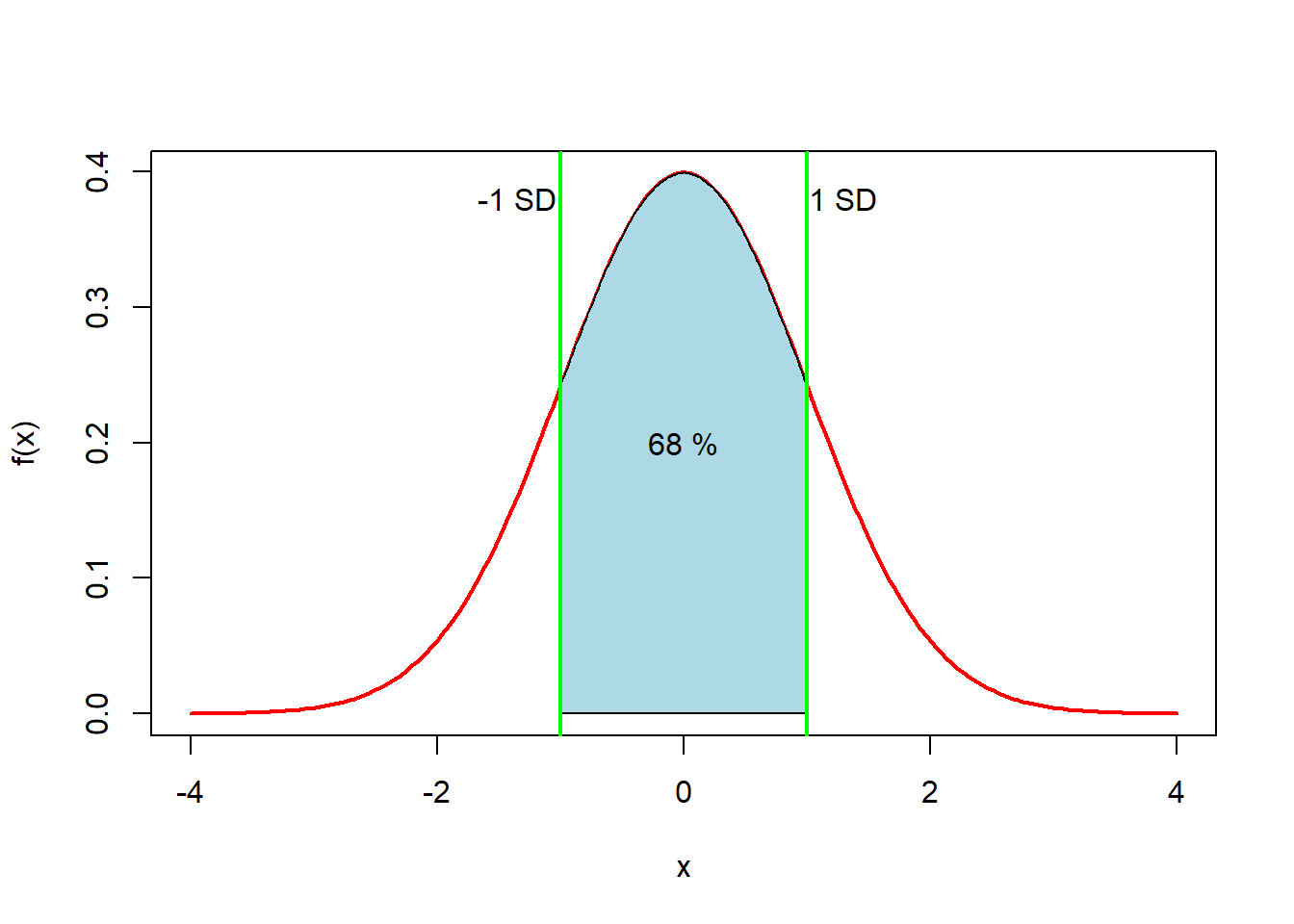
Figure 4.6: Normalfordeling med 1 standardavvik
Ett standardavvik “over og under” 0 (= det skraverte området i grafen over) innebærer at det er 68 % sannsynlighet for at en tilfeldig valgt x-verdi befinner seg i dette intervallet. Vi kan vise det samme for 2 og 3 standardavvik:
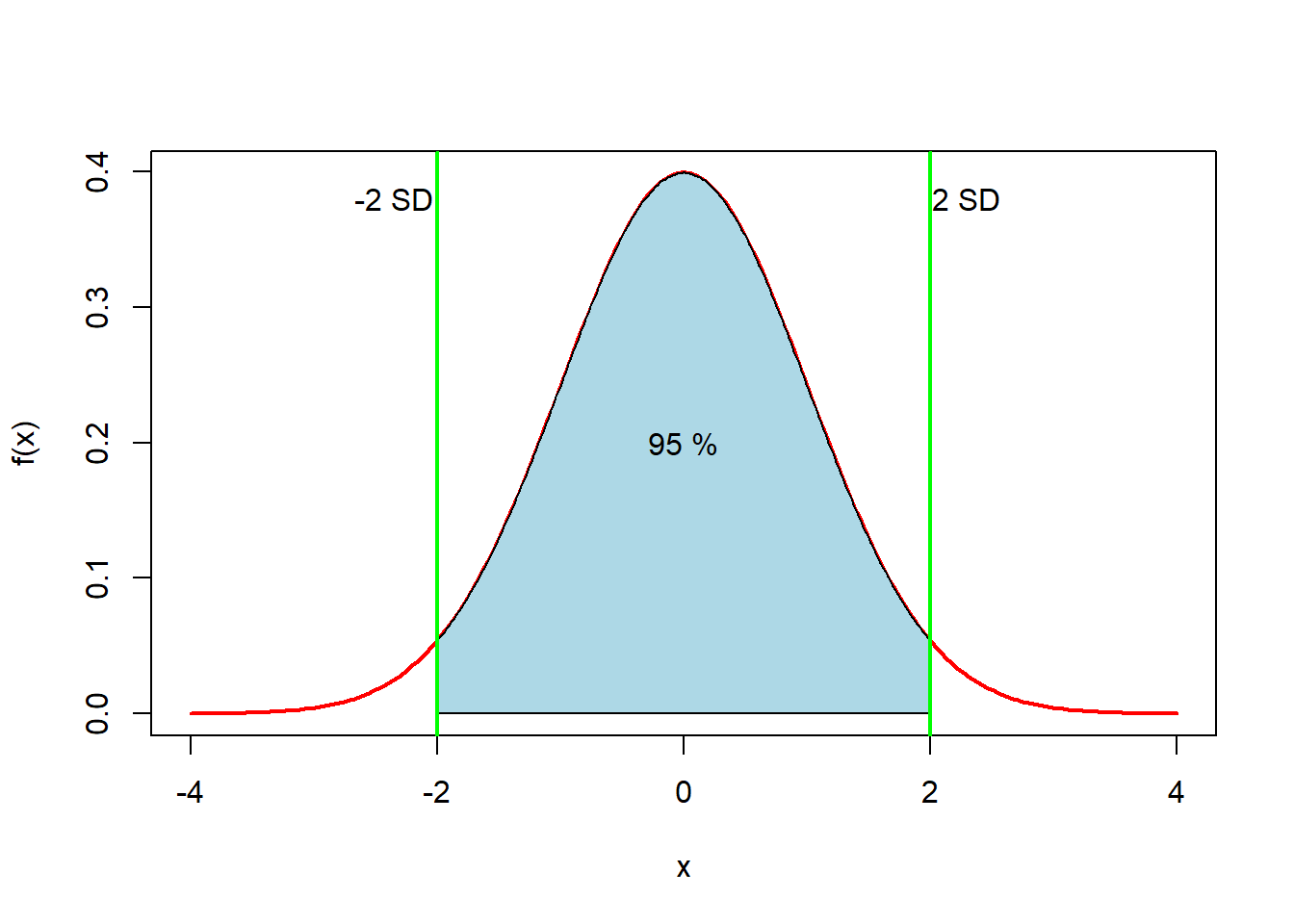
Figure 4.7: Normalfordeling med 2 standardavvik
To standardavvik “over og under” 0 (= det skraverte området i grafen over) innebærer at det er 95 % sannsynlighet for at en tilfeldig valgt x-verdi befinner seg i dette intervallet. Vi kan finne arealet mellom x=-2 og x=2, som er 0.954499713.
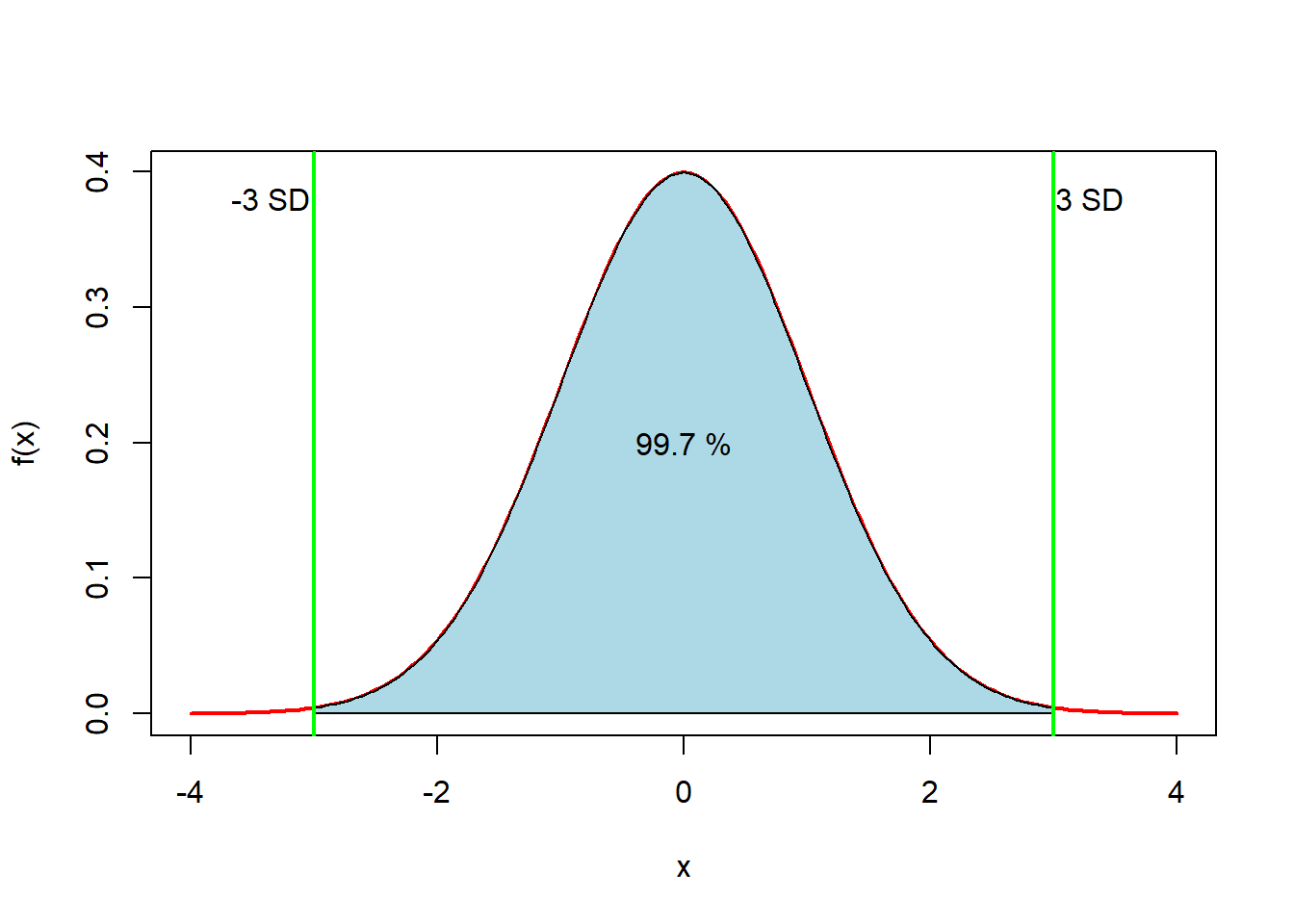
Figure 4.8: Normalfordeling med 3 standardavvik
Tre standardavvik “over og under” 0 (= det skraverte området i grafen over) innebærer at det er 99.7 % sannsynlighet for at en tilfeldig valgt x-verdi befinner seg i dette intervallet. Vi kan finne arealet mellom x=-3 og x=3, som er 0.997300214. Dette utgjør et kjernepunkt i statistisk prosesskontroll som vi vil komme mye tilbake til.
Oppsummert kan vi framstille normalfodeling og standardavvik slik (Hartmann, Krois, and Waske 2018b):
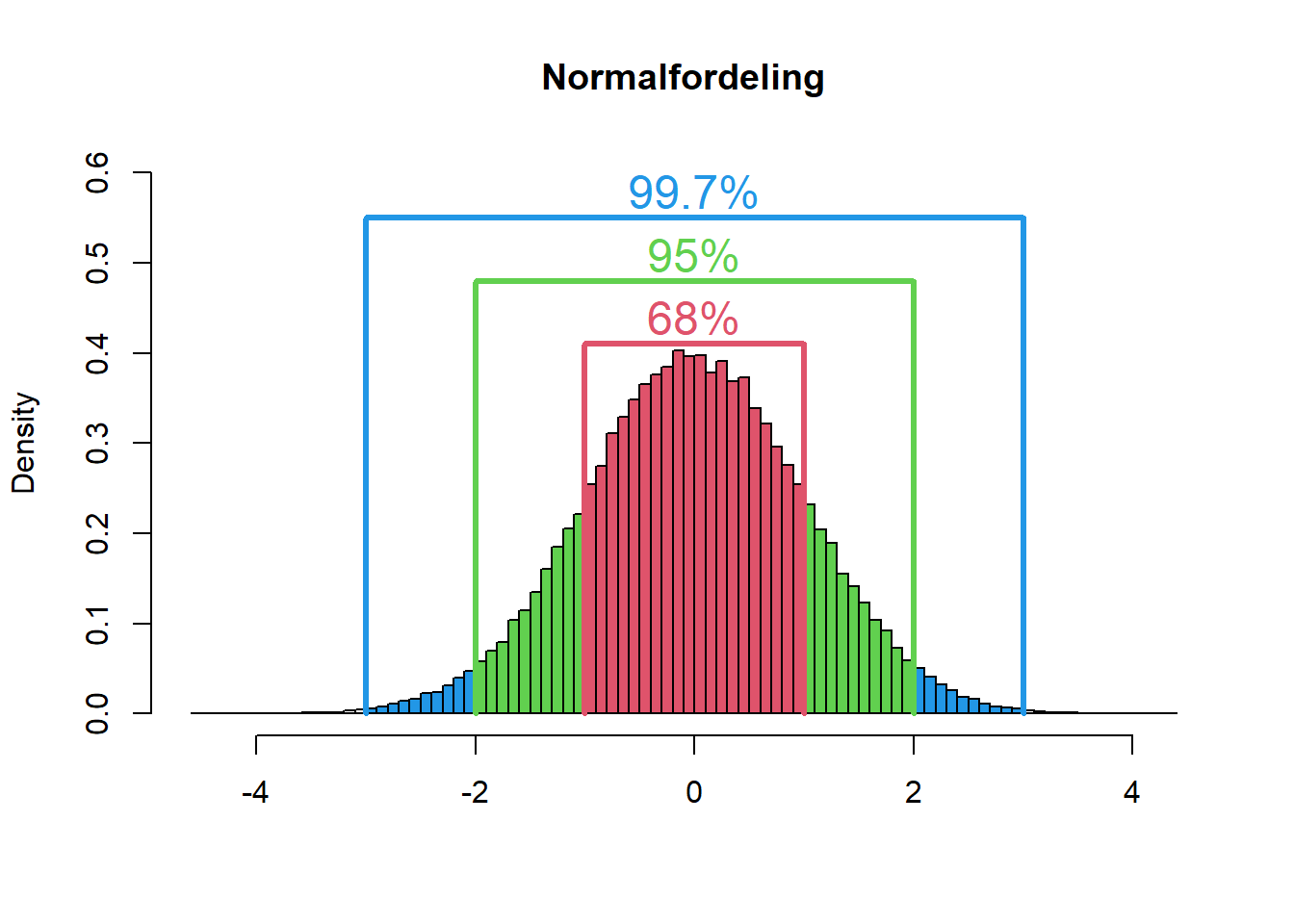
Figure 4.9: Normalfordeling med standardavvik
Som nevnt er mange fenomener i hverdagen normalfordelte, eller nærme nok normalfordeling til at vi kan bruke normalfordeling som teoretisk modell for observerte data 15. Det finnes imidlertid mange tilfeller der vi ikke kan bruke normalfordelingen. Hvis dataene er sterkt asymmetriske vil ikke reglene for normalfordeling som vi har skissert ovenfor gjelde 16. Noen av de er viktige for statistisk prosesskontroll, og de vil vi se på i de følgende avsnittene.
4.2 Binomialfordeling
En distribusjon hvor det kun er to mulige utfall av en hendelse kalles en binomial fordeling. Et myntkast er en slik hendelse (gitt at vi ser bort fra den fysiske muligheten at mynten kan lande stående på høykant). Levende eller død kan også være et eksempel på dette. Det ene utfallet utelukker det andre, men de er uavhengige fordi resultatet i ett myntkast ikke påvirker resultatet i neste myntkast. Alle myntkastene må derimot være identiske, det vil si sannsynligheten for det ene eller det andre resultatet er lik hver gang forsøket eller myntkastet gjennomføres. Hvis vi har lik sannsynlighet, kan en tilfeldig generert binomial distribusjon se slik ut:
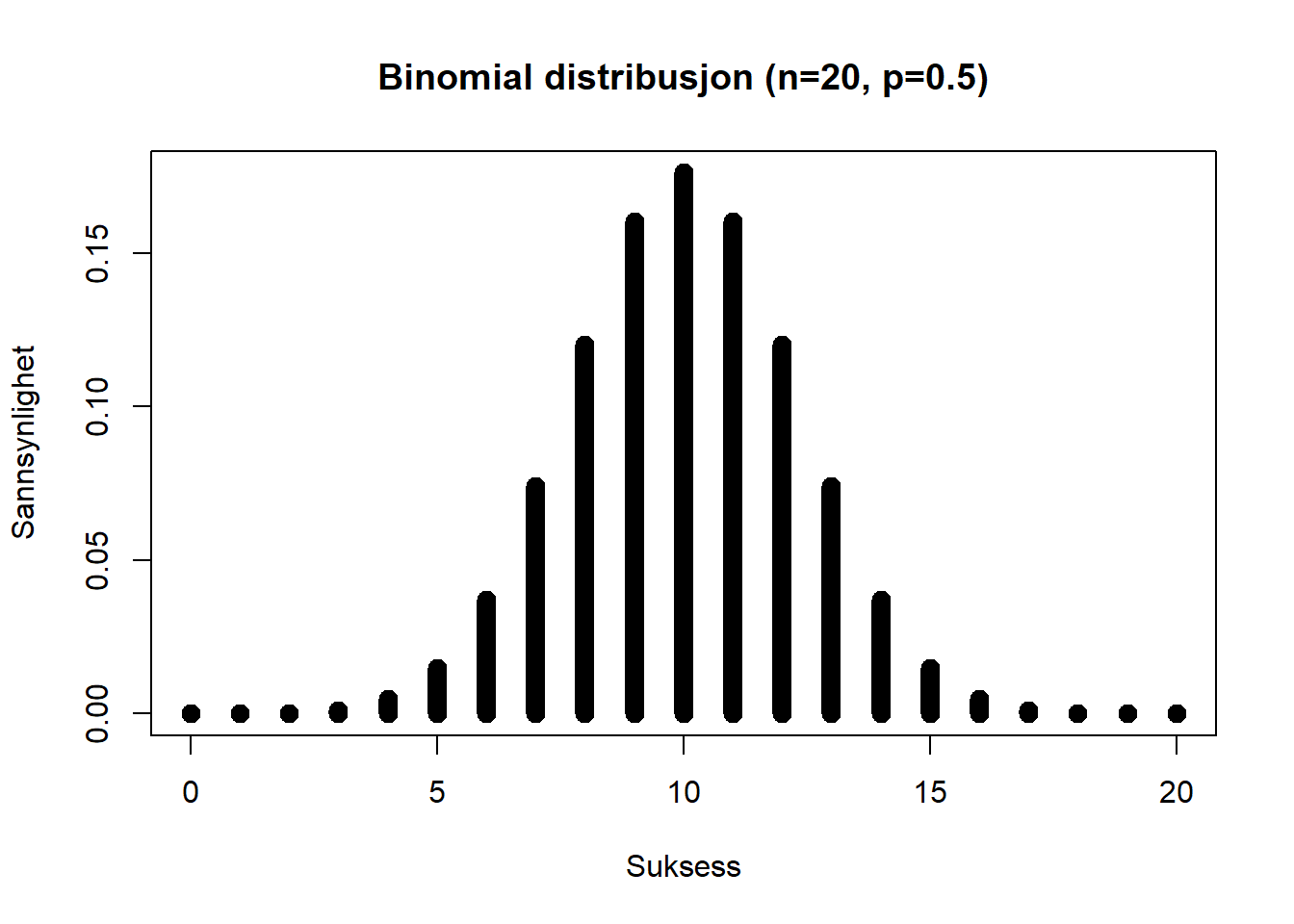
Figure 4.10: Binomialfordeling med lik sannsynlighet
I diagrammet over vises en sannsynlighetsfordeling for en binomial fordeling der utfallene suksess/fiasko har lik sannsynlighet. Hvis vi gjennomfører en aktivitet med disse karakteristika 20 ganger kan vi bruke sannsynlighetsfordelingen til å skape en forventning om sannsynligheten for antall suksesser/fiaskoer. Hver gang vi gjennomfører aktiviteten blir det enten suksess eller fiasko. Hvis vi har 50% sjanse for suksess eller feil hver gang vi gjennomfører aktiviteten er sannsynligheten for suksess lik som sannsynligheten for fiasko. Vi kan da forvente at det er størst sannsynlighet at vi i 10 av 20 tilfeller får suksess. Det er liten sannsynlighet for at vi enten får suksess i 0 eller 20 av 20 ganger vi gjør aktiviteten.
Det er imidlertid verdt å merke seg at de to utfallene ikke trenger å ha lik sannsynlighet. Da vil den binomiale distribusjonen se annerledes ut:
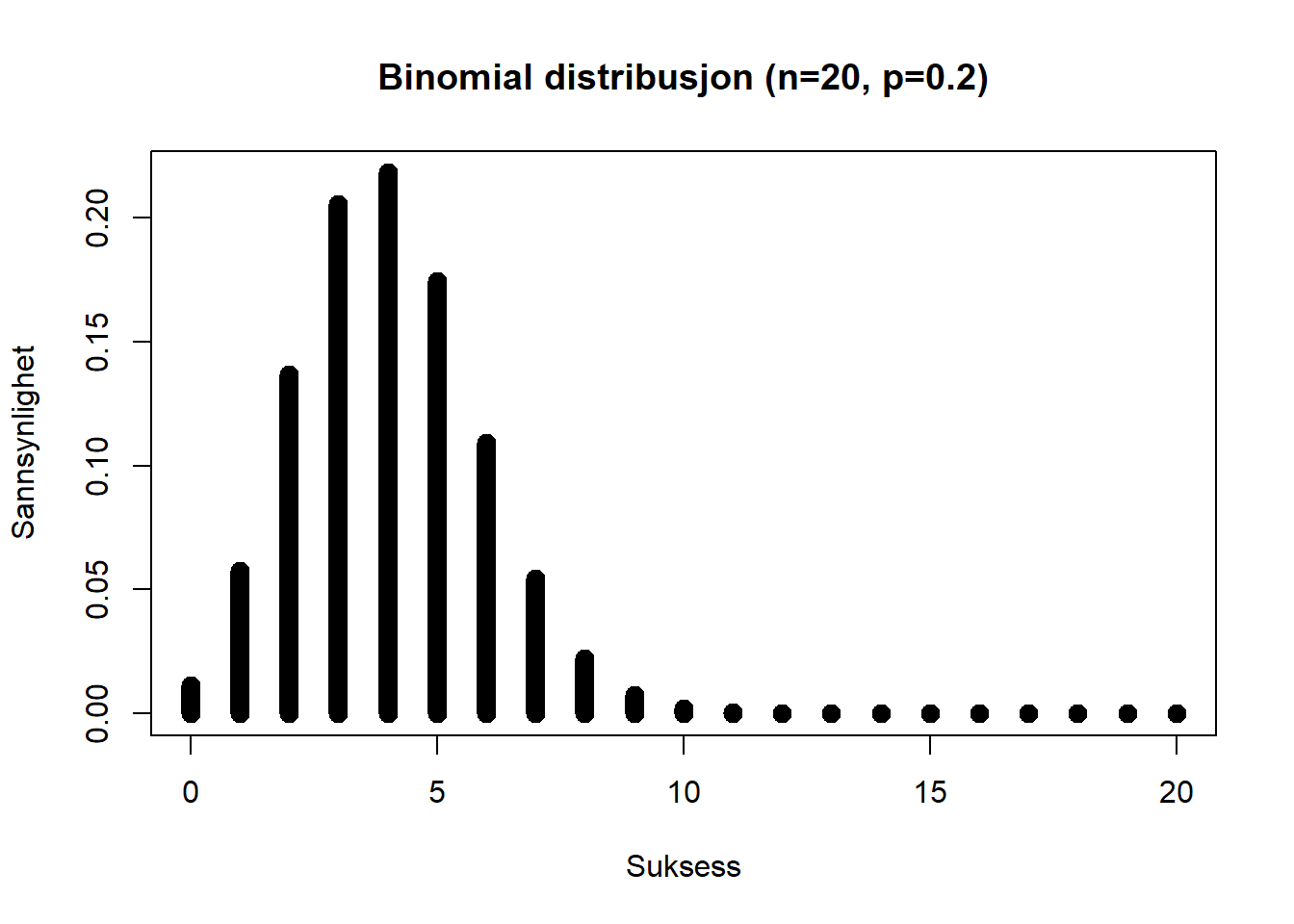
Figure 4.11: Binomialfordeling med ulik sannsynlighet
Her har vi bare 20% sannsynlighet for suksess, og fordelingen av sannsynligheter vil se annerledes ut. Med 20% sannsynlighet for suksess er det veldig liten sannsynlighet for at vi vil få 10 eller flere suksesser hvis vi gjør forsøket 20 ganger. Det er størst sannsynlighet for å få 4 suksesser.
Et terningkast (med en vanlig terning med 6 sider) – som ikke er tuklet med – har lik sannsynlighet for å lande på hhv 1,2,3,4,5 og 6. Det vil si det er 1/6 sannsynlighet for 1, 1/6 sannsynlighet for 2 osv. Hvis vi kaster denne terningen 10 ganger kan resultatet se slik ut:
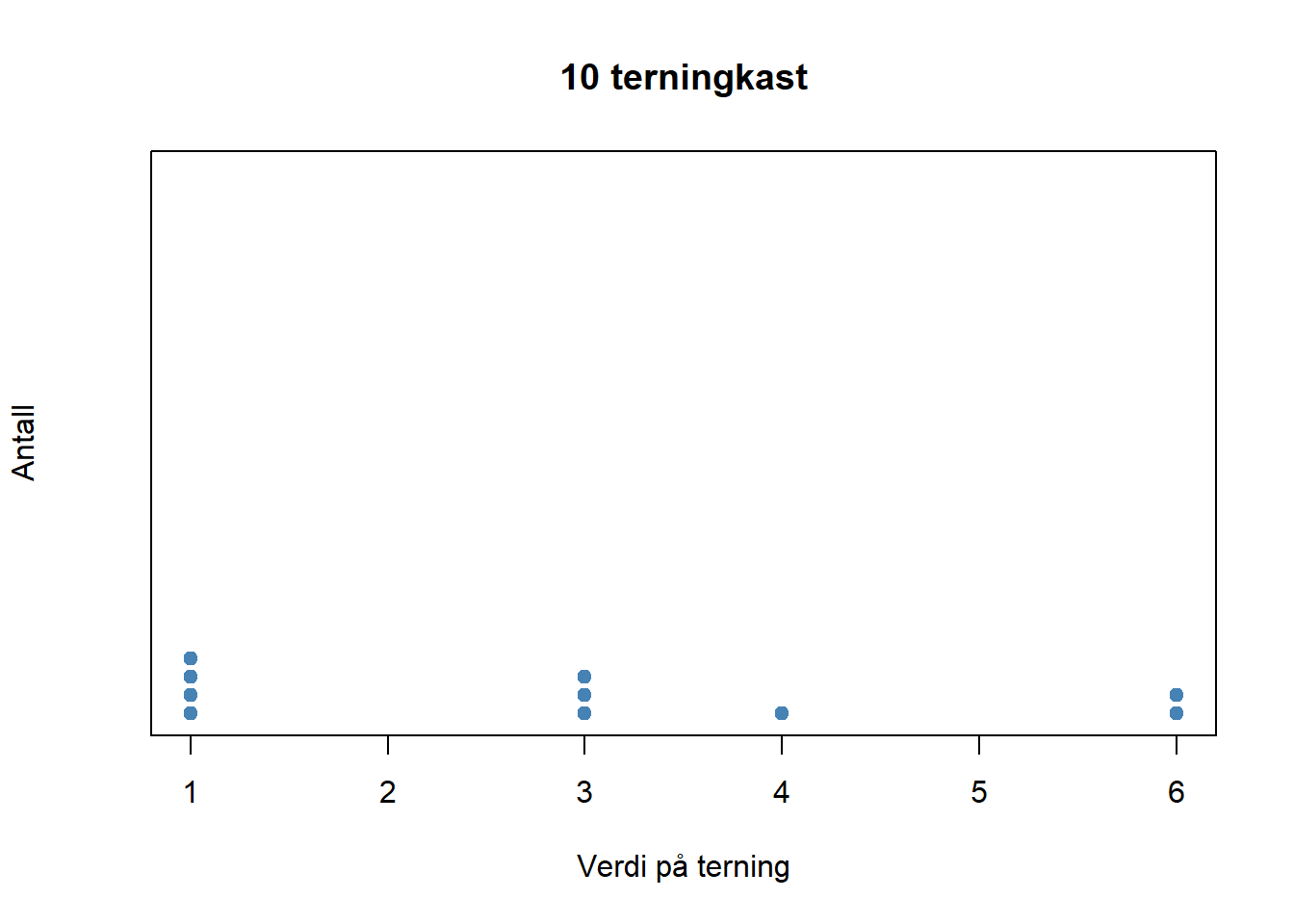
Figure 4.12: 10 terningkast
Vi ser at vi ikke fikk noen 2’ere og 5’ere. Dette kan vi forvente når vi bare har 10 terningkast. Hvis vi imidlertid kaster terningen 100 ganger vil det være svært liten sannsynlighet for å ikke få «treff» på alle 6 verdiene på terningen, og vi burde kunne forvente at vi får en ganske jevn fordeling på alle 6 verdiene. Nedenfor vises resultatet av 100 terningkast.

Figure 4.13: 100 terningkast
Vi ser at vi har en relativt jevn fordeling. Noe ulikhet er det selvsagt, noe vi vil forvente fra en tilfeldig prosess. Hvis vi gjennomførte 1000 eller 10000 terningkast vil fordelingen bli nærmere og nærmere den teoretisk forventede fordelingen. Vi kan burde, teoretisk, forvente 100 treff på hver mulighet hvis vi kaster terningen 600 ganger, men vi vil sjelden se akkurat 100 treff på hver slik vi ser hvis vi kjører tre runder med 600 terningkast:
Runde 1:
## terning_runde1
## 1 2 3 4 5 6
## 93 102 102 102 108 93Runde 2:
## terning_runde2
## 1 2 3 4 5 6
## 101 102 94 91 105 107Runde 3:
## terning_runde3
## 1 2 3 4 5 6
## 104 113 92 98 95 98Selv om vi kjører 6 000 000 terningkast og vil forvente 1 000 000 treff på hver av terningens sider vil vi ikke få en perfekt fordeling iht teoretisk forventning, men resultatet vil være svært nærme og er nærme nok til at vi kan bruke sannsynlighetsfordelingen til å lage forventninger om utfall:
6 000 000 terningkast:
## minterning
## 1 2 3 4 5 6
## 1000492 998250 1000216 1000832 1001422 998788Hvis vi setter resultatet fra 6 000 000 terningkast inn i et histogram ser vi at resultatet er svært nærme hva vi teoretisk vil forvente:
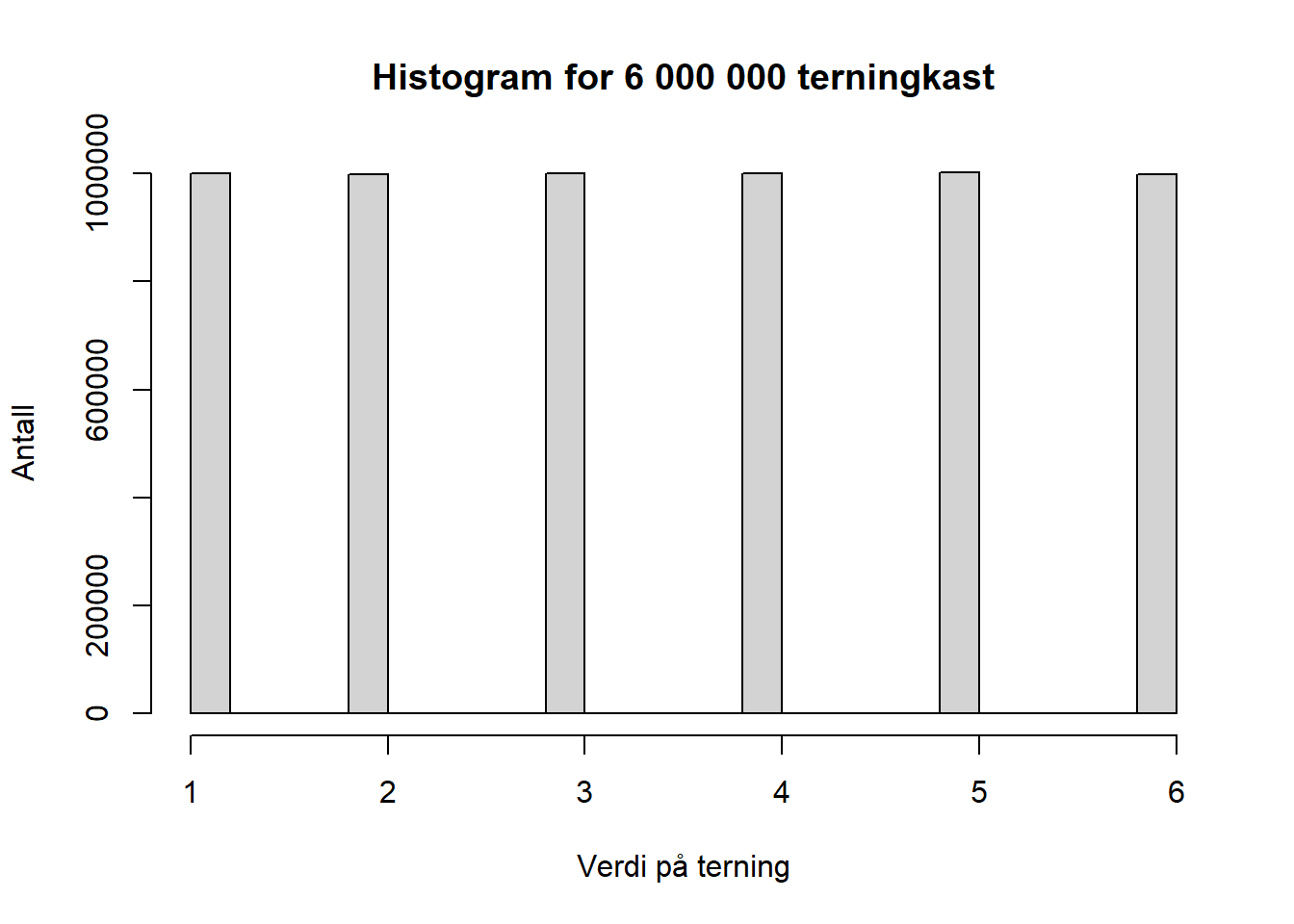
Figure 4.14: 6 000 000 terningkast
4.3 Poissonfordeling
Poissonfordelinger finnes i situasjoner der hendelser skjer vilkårlig i tid (og rom) hvor vi er interessert i kun antallet hendelser i et gitt tidsintervall. Vi kan f.eks. være interessert i hvor mange supporthenvendelser vi får i løpet av en time, antallet feilmedisineringer per uke, hvor mange besøk avdelingen får per dag o.l. Andre eksempler kan være antall trafikkulykker langs en angitt veistrekning, antall elgpåkjørlser på en togstrekning, eller antall av en gitt art fugler i et definert område i et definert tidsrom. En hendelse må være uavhengig tidsmessig av andre hendelser (det er altså ikke økt sannsynlighet for at en hendelse vil skje fordi en tilsvarende hendelse akkurat har skjedd), sannsynligheten for en hendelse i et kort perspektiv er lik sannsynligheten over et lengre perspektiv, og ettersom et tidsintervall blir kortere og kortere vil sannsynligheten for hendelsen gå mot null.
Poissonfordeling uttrykker sannsynligheten for at et gitt antall hendelser inntreffer i et gitt tidsintervall (eller et gitt geografisk domene) og at vi kjenner gjennomsnittlig hvor ofte hendelsen inntreffer. Denne sannsynligheten uttrykkes som en lambdaverdi (\(\lambda\)).
Eksempelet under er hentet fra Soage (2020):
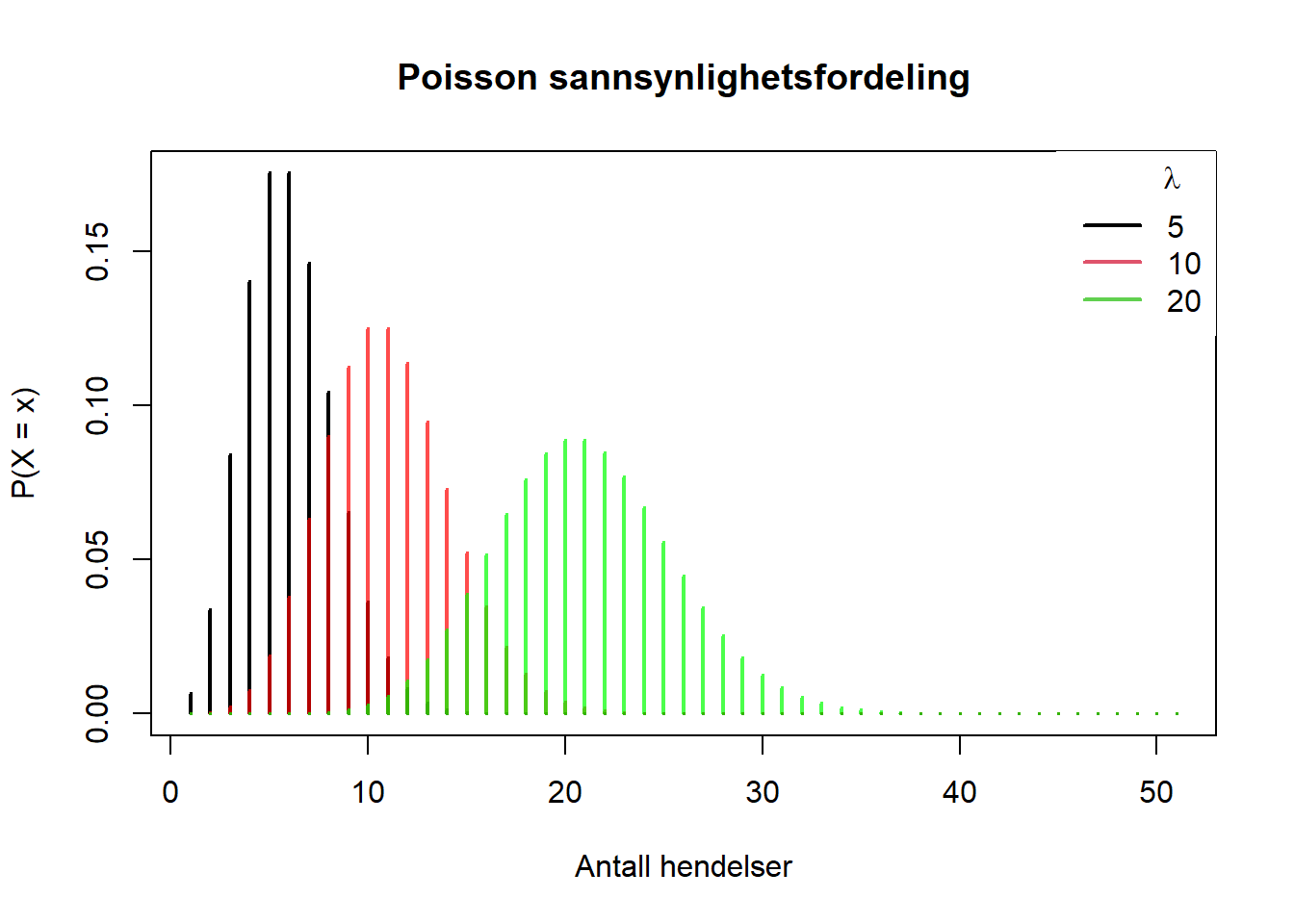
Figure 4.15: Poissonfordelinger
Ut fra hvilken \(\lambda\)-verdi vi setter kan vi si noe om sannsynligheten for at et antall hendelser inntreffer.
Ugarte et al. (2016) eksemplifiserer Poissonfordeling ved å vise til at det i gjennomsnitt skåres 2,5 mål i en VM-kamp i fotball. Denne situasjonen tilfredsstiller forutsetningene for å bruke Possionfordeling.Vi kan grafisk framstille sannsynlighetsfordeingen slik:
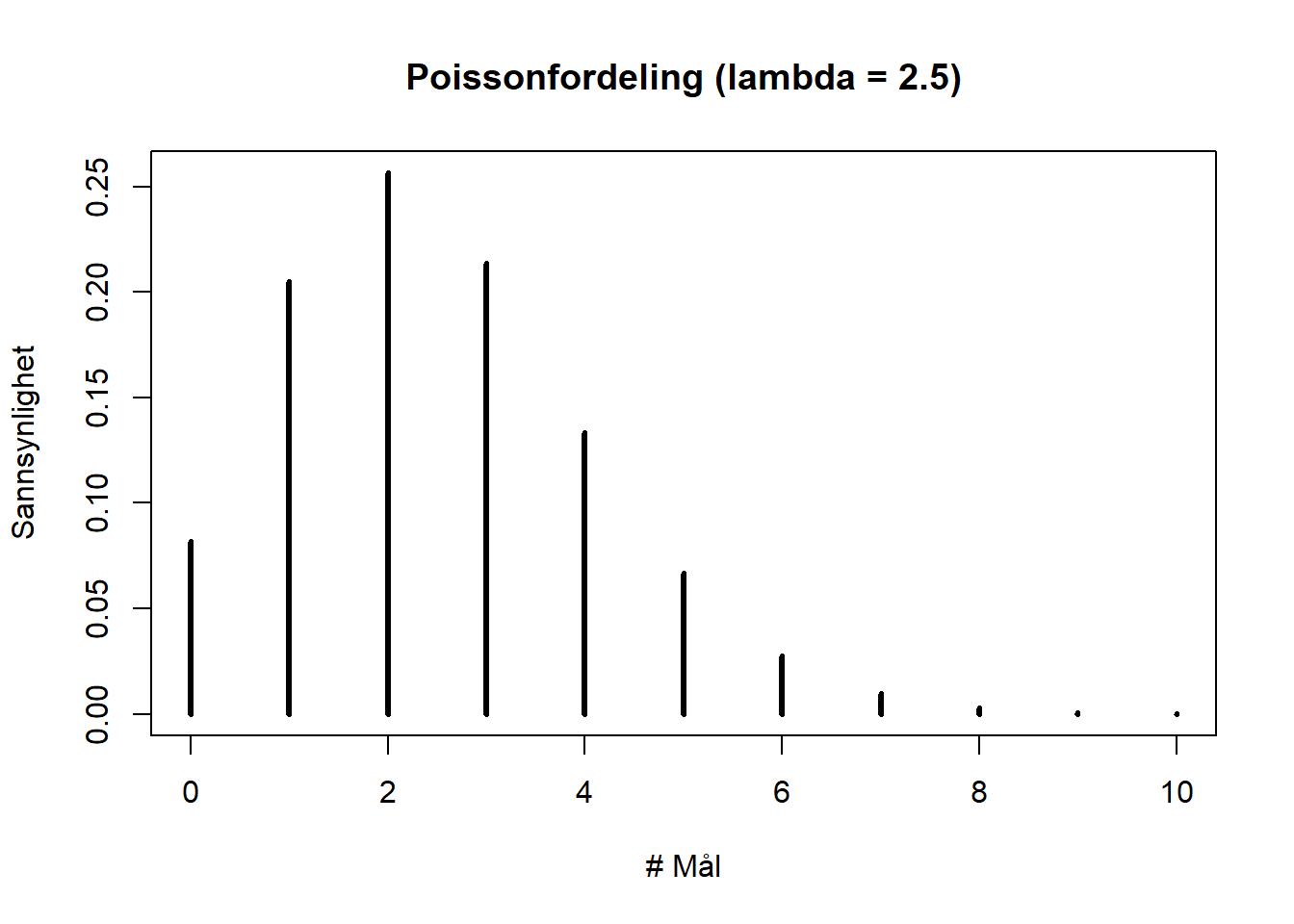
Figure 4.16: Poissonfordeling mål i VM-kamp fotball
I R kan vi også enkelt regne ut den nøyaktige sannsynligheten for x antall mål gitt forutsetningen om at det i snitt skåres 2.5 mål pr kamp til å være 0. Vi kan bruke sannsynlighetsfordelingen til å regne ut sannsynligheten for et gitt antall mål, f.eks.:
- Sannsynligheten for 0 mål = 0.082085
- Sannsynligheten for 1 mål = 0.2052125
- Sannsynligheten for 2 mål = 0.2565156
- Sannsynligheten for 3 mål = 0.213763
- Sannsynligheten for 4 mål = 0.1336019
eller f.eks. sannsynligheten for at det skåres mellom 1 og 3 mål (= 0.6754911).
4.4 Geometrisk fordeling
En geometrisk fordeling er en diskret fordeling der man teller antall hendelser/forsøk inntil et gitt resultat forekommer. Resultatet er suksess eller feil, altså hvor mange ganger man har en hendelse før man får en suksess eller feil (avhengig av hva man måler). Et eksempel er hvor mange ganger man må kaste to terninger for å få 11 i sum. Man kaster da to terninger til første gang man får 11 (= suksess). En geometrisk distribusjon kan se slik ut (p = 0,4):
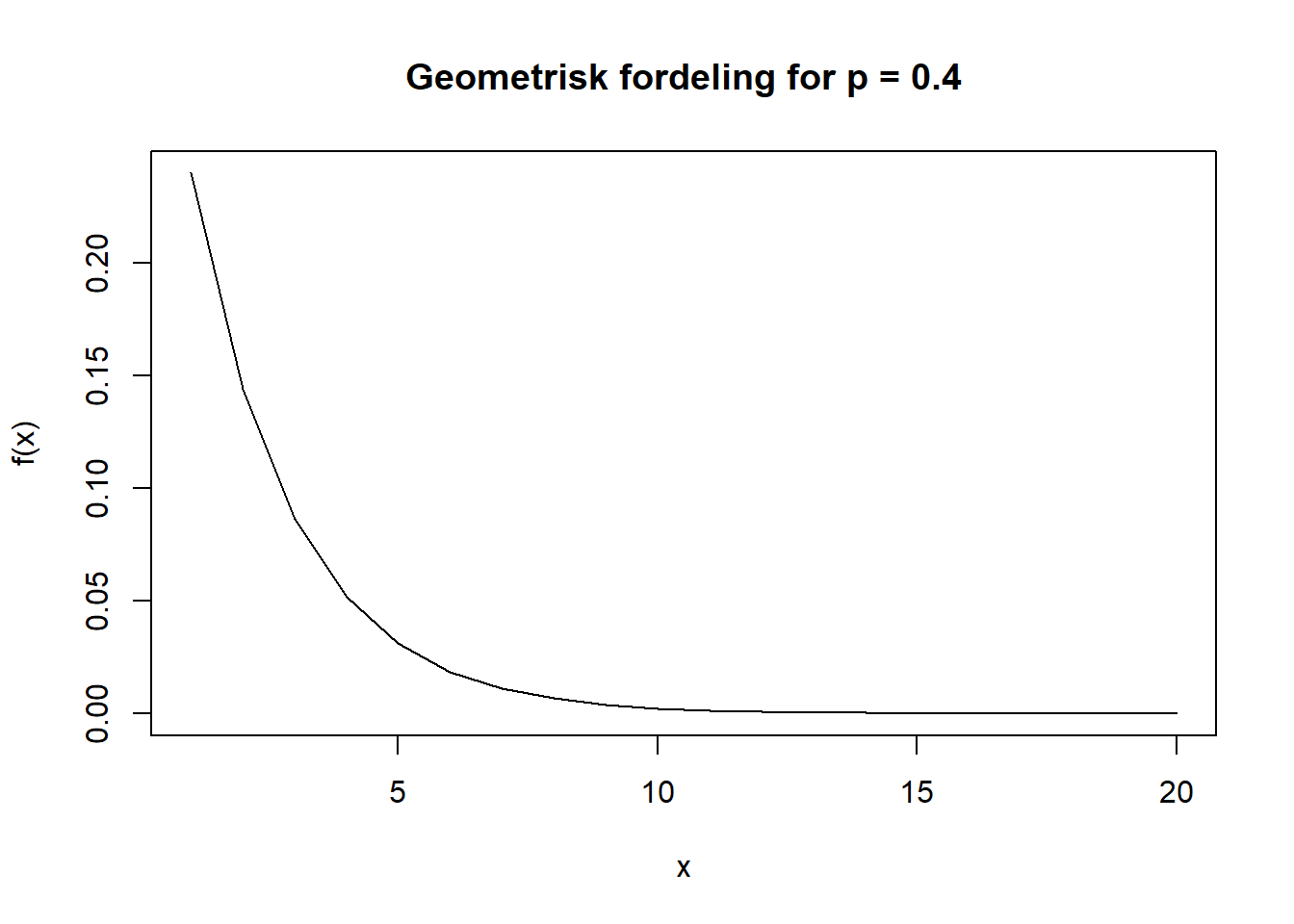
Figure 4.17: Geometrisk fordeling
I statistisk prosesskontroll er denne typen fordeling til stede når man f.eks. teller antall dager mellom sjeldne hendelser. Man teller antall dager før man f.eks. får et alvorlig avvik på en medisinering, en operasjon e.l. I geometrisk fordeling er sannsynligheten for et gitt utfall uavhengig av om det har skjedd før. Man kan bruke geometrisk fordeling f.eks. til å estimere hvor mange dager man normalt vil forvente det går mellom en sjelden hendelse. Hvis man gjennom erfaringstall vet at sannsynligheten for en sjelden hendelse er p = 0.035 vil man forvente at det går 1/0.035 \(\approx\) 29 dager mellom hver hendelse. Geometrisk distribusjon kan hjelpe oss i en statistisk prosesskontroll for å finne normal/unormal variasjon ved sjeldne hendelser.
Det kan være verdt å merke seg at binomial og geometrisk fordeling skiller seg fra hverandre ved at geometrisk fordeling har et ukjent antall hendelser (man fortsetter til man får første suksess/feil), mens binomial fordeling har et gitt antall hendelser. Som vi skal se i senere eksempler derfor geometrisk fordeling viktig når vi håndterer sjeldne hendelser, fordi vi ikke kjenner hvor mange dager det f.eks. går før vi får første suksess/feil.
4.5 Eksponensiell fordeling
En tilfeldig kontinuerlig variabel kan sies å være analog til den geometriske distribusjonen, men for kontinuerlige data. Den eksponensielle distribusjonen brukes ofte for å modellere tid mellom to hendelser. I statistisk prosesskontroll vil vi typisk bruke denne distribusjonen hvis vi måler tid mellom to sjeldne hendelser. Hvis vi f.eks. måler tiden mellom uventet dødsfall som følge av en type rutineoperasjon på et sykehus vil den ha en eksponensiell distribusjon hvis sannsynligheten for at hendelsen inntreffer innenfor t gitt tidsintervall er omtrentlig proporsjonal med lengde på tidsintervallet (Taboga 2017). Eksponensielle fordelinger har samme grunnform, men kan ha ulik bratthet avhengig av den såkalte lamdaverdien (= en parameter for raten av hendelser). Lambdaverdi er en parameter for hvor ofte hendelsene forventes å skje.
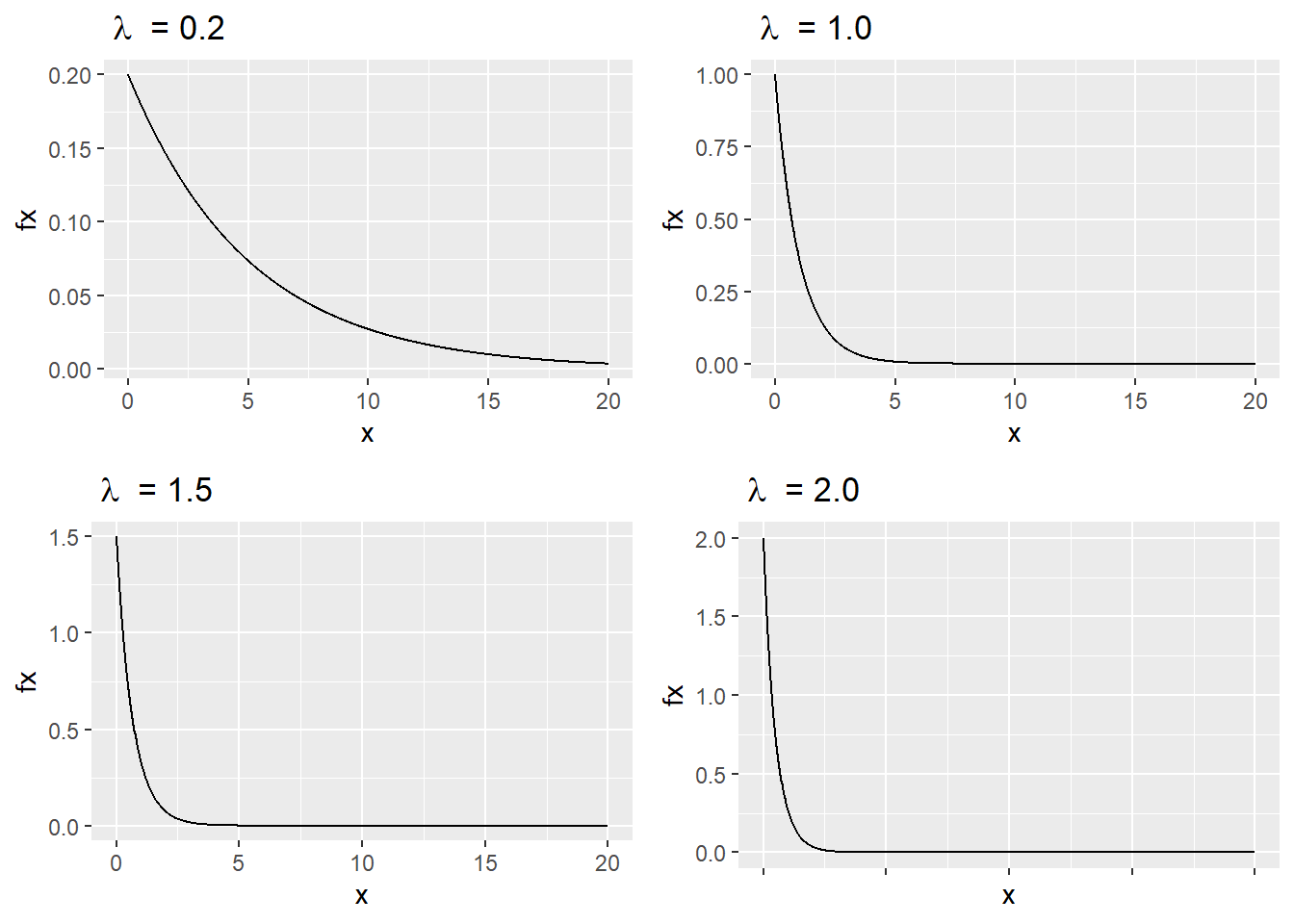
Figure 4.18: Eksponensiell fordeling