7 Kontrolldiagram
Et kontrolldiagram er mer sensitivt for å vise spesielle typer variasjon enn et run diagram. For å oppnå denne økte sensitiviteten er det imidlertid viktig at man velger riktig type kontrolldiagram ut fra hvilken type data man har. Her vil flytdiagrammet på s.xxxx kunne være til hjelp for å velge riktig type, men vi vil også gå gjennom hvert enkelt kontrolldiagram nedenfor. Man skal imidlertid ikke anta at et seriediagram er «mindre verdt» enn et kontrolldiagram. Selv om kontrolldiagram er mer sensitive ovenfor spesielle typer variasjon, er seriediagram mer sensitive ovenfor mindre skifter i dataene (under 2 SD) enn kontrolldiagrammene som typisk reagerer på større skifter i dataene (rundt 2 SD og mer) (Anhøj and Olesen 2014). Et seriediagram kan derfor ofte være et viktig første steg før man tar i bruk mer sofistikerte verktøy som kontrolldiagram (Perla et al. 2011).
En spesiell egenskap ved kontrolldiagram er at den kan hjelpe oss til å se yteevnen til en stabil prosess. Med det mener vi hvilke grenser prosessen trolig vil holde seg innenfor. Dette kalles ofte for prosesskapabilitet. Dette vil vi komme nærmere tilbake til i et senere avsnitt.
Så hva er et kontrolldiagram? Et kontrolldiagram er en statistisk tilnærming til å se på prosesser, variasjon i prosesser og om prosesser produserer resultater innenfor gitte akseptable grenser. Det likner på i stor grad på et seriediagram. Vi plotter inn en rekke hendelser eller observasjoner i et diagram der tiden for observasjonene plottes fortløpende i tid på x-aksen og verdien eller antall hendelser på y-aksen. Det et kontrolldiagram tilfører er at det inkluderer mer avanserte analyser gjennom å regne ut to kontrollgrenser som lar oss vurdere statistisk etter andre regler enn seriediagrammet om en prosess har normal eller unormal variasjon. I tillegg er kontrolldiagrammene basert på at sentraltendensen er gjennomsnittet, ikke median (som i seriediagrammet).
Shewhart baserte sin tilnærming til kontrolldiagram på matematisk teori (se vedlegg 7 for forklaring på Chebyshevs teorem) og egne empiriske erfaringer når han satt verdiene for øvre og nedre kontrollgrenser til tre sigma (tre standardavvik). Flere tiårs erfaring fra en lang rekke områder viser at tre sigma som grenseverdier holder vann (Mohammed, Worthington, and Woodall 2008).
Et kontrolldiagram kan se slik ut (R pakken qicharts2 (Anhøj 2020):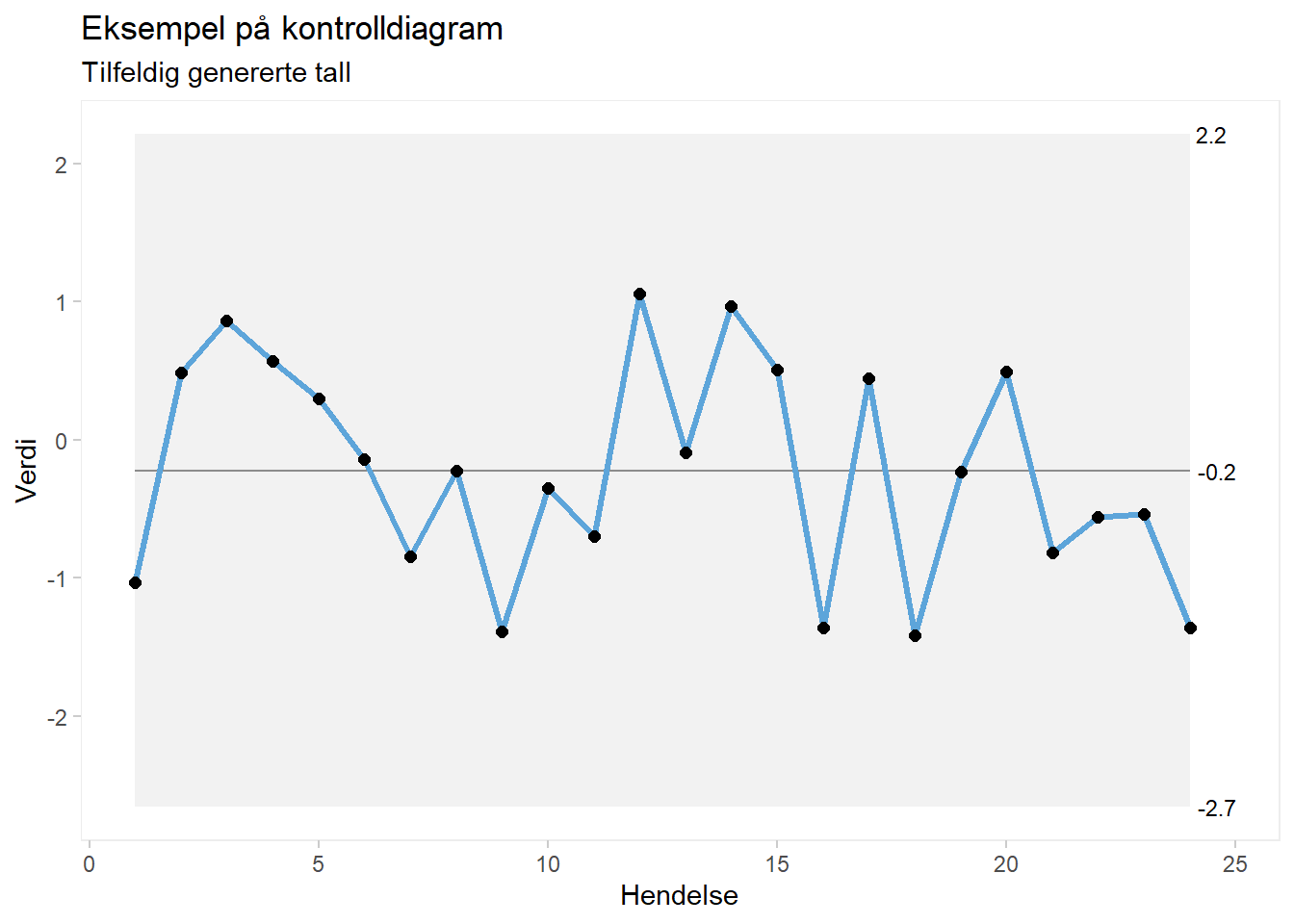
Figure 7.1: Eksempel kontrolldiagram i qicharts
Observasjonene/målingene plottes som punkter sekvensielt i tid. Snittet er -0,2, UCL 2,2 og LCL -2,7.
Tilsvarende data ved bruk av R pakken qcc (Scrucca et al. 2017):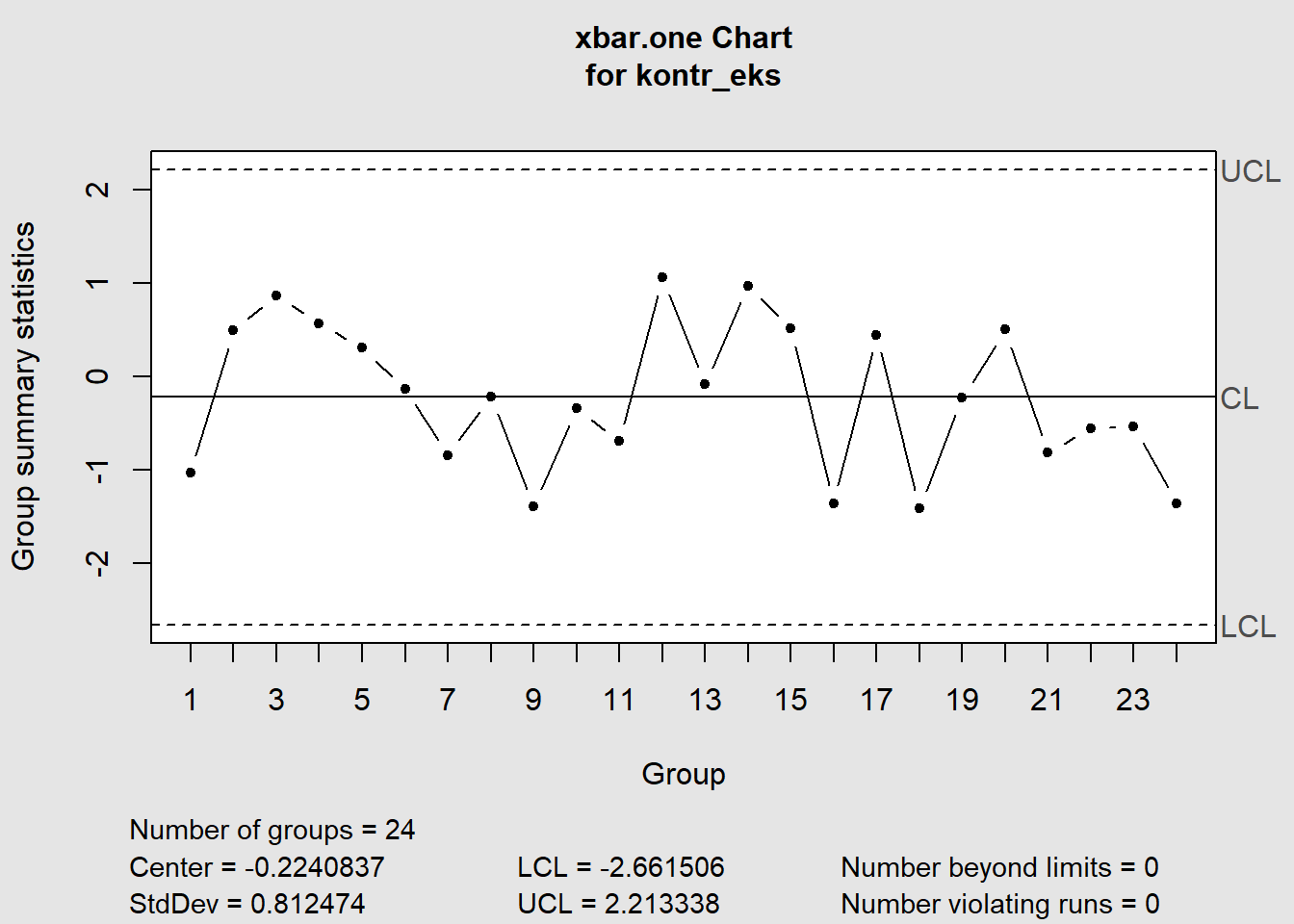
Figure 7.2: Eksempel kontrolldiagram i qcc
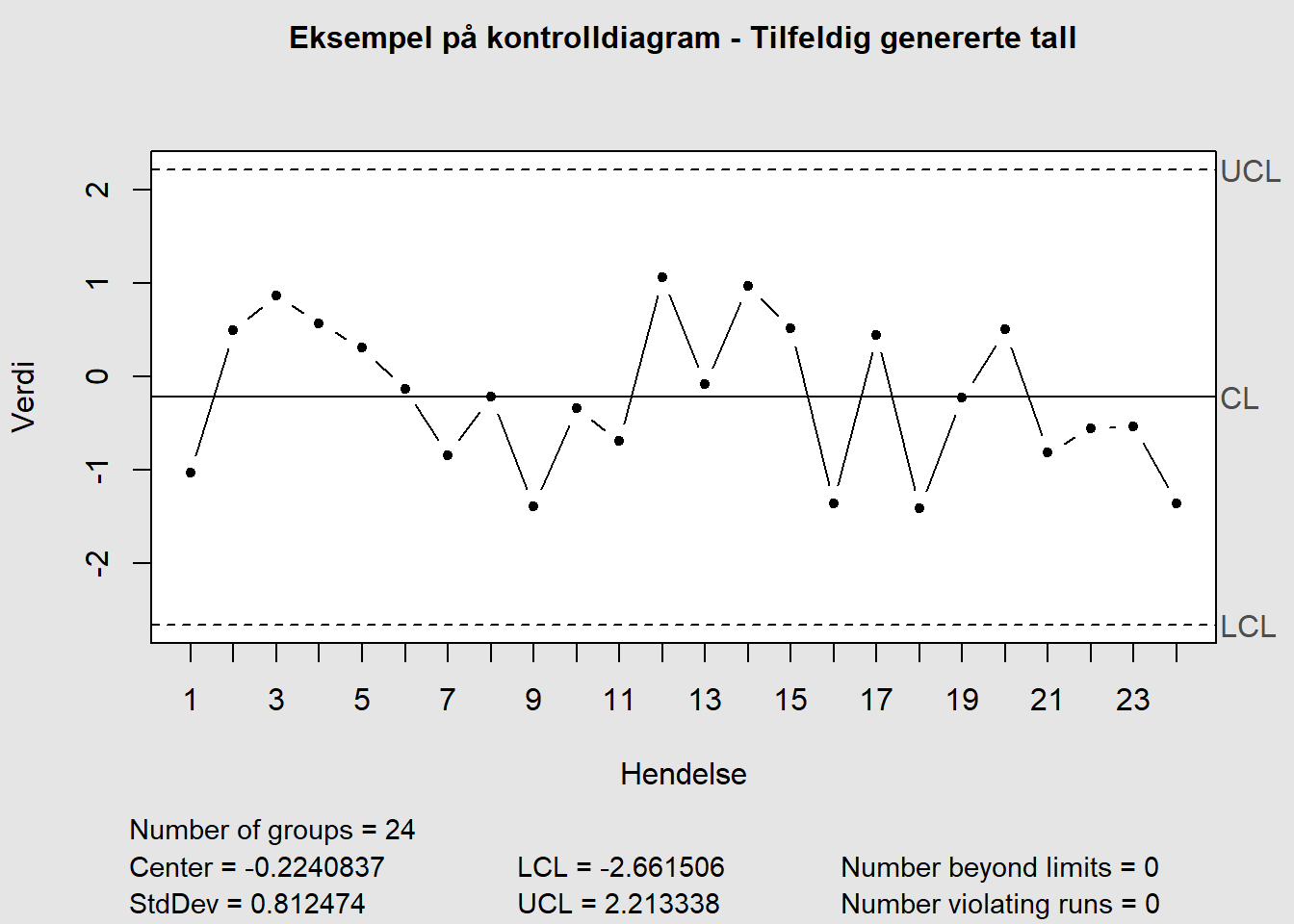
Figure 7.3: Eksempel kontrolldiagram i qcc
Alle kontrolldiagram vil ha tre horisontale linjer: En gjennomsnittsverdi, en øvre kontrollgrense og en nedre kontrollgrense (øvre og nedre kontrollgrense kan ved enkelte typer kontrolldiagram avvike fra en ren horisontal linje, men ha et horisontalt mønster.
Ulike programmer eller R-pakker gir ulik grafisk framstilling.Analyse-It i Excel gir dette for samme data:
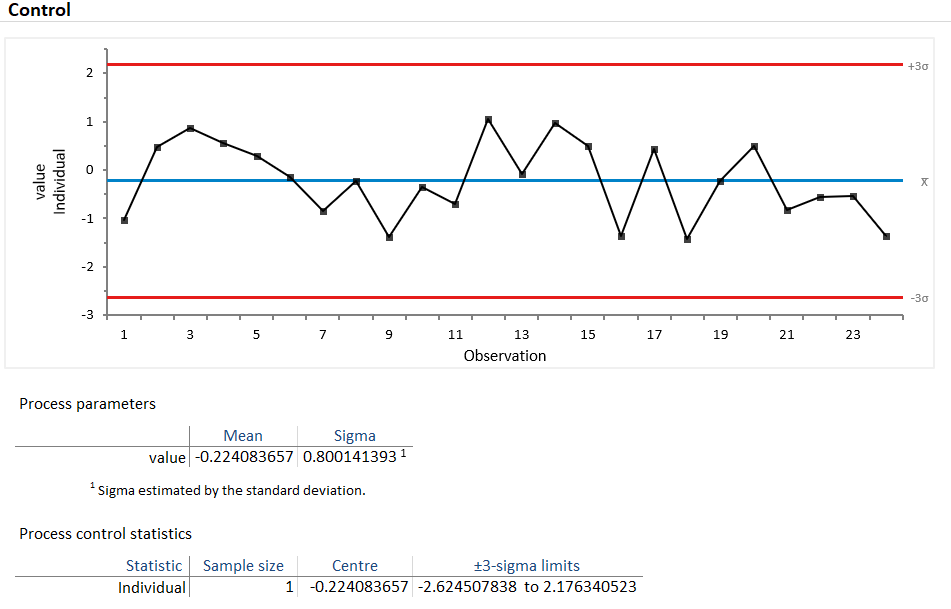
Før vi går inn på kontrolldiagram for hhv telledata og måldata skal vi ta en gjennomgang av typiske mønstre som trekkes fram som kan si oss noe om tolkning av kontrolldiagram (se f.eks. Lavangnananda and Tengsriprasert (2002) og Montgomery (2020)).
7.1 Mønstre i kontrolldiagram
Når vi har laget et kontrolldiagram vil det være noen åpenbare tegn vi vil legge merke til, f.eks. vil vi ganske raskt se om vi har punkter utenfor kontrollgrensene. En annen ting vi raskt kan forsøke å se på er om kontrolldiagrammet viser et gjenkjennbart mønster som kan fortelle oss noe om prosessen og dataene vi har. Vi skal her vise åtte typiske mønstre som blir av flere blir trukket fram (Lavangnananda and Tengsriprasert (2002) snakker om ni mønster, der det siste omtales som “Mixture” - vi mener imidlertid den i praksis kan være så vanskelig å fange opp eller skille fra et normalt mønster at vi velger å se bort fra denne). Vi viser mønstrene uten mange kommentarer da de fleste er ganske åpenbare.
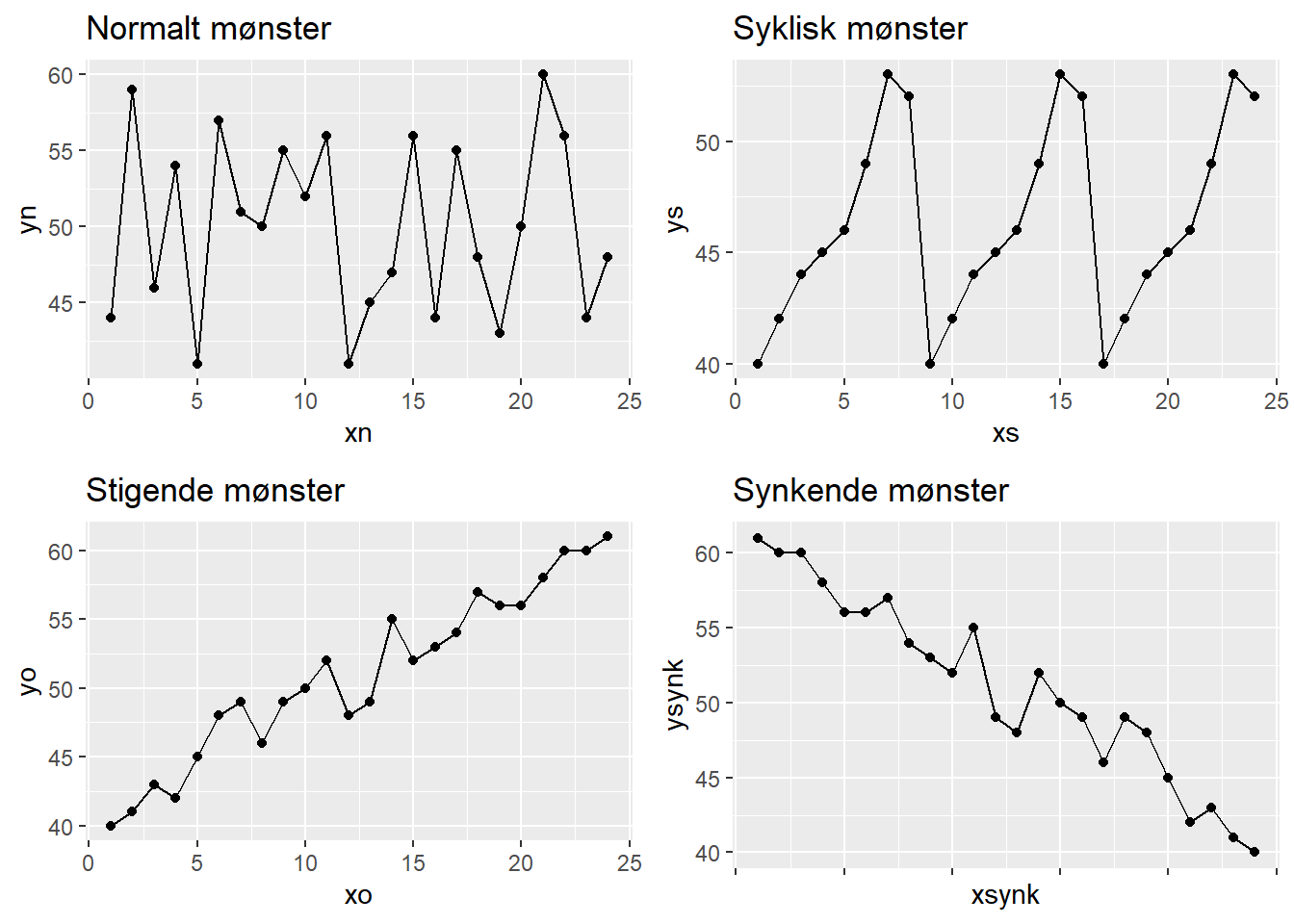
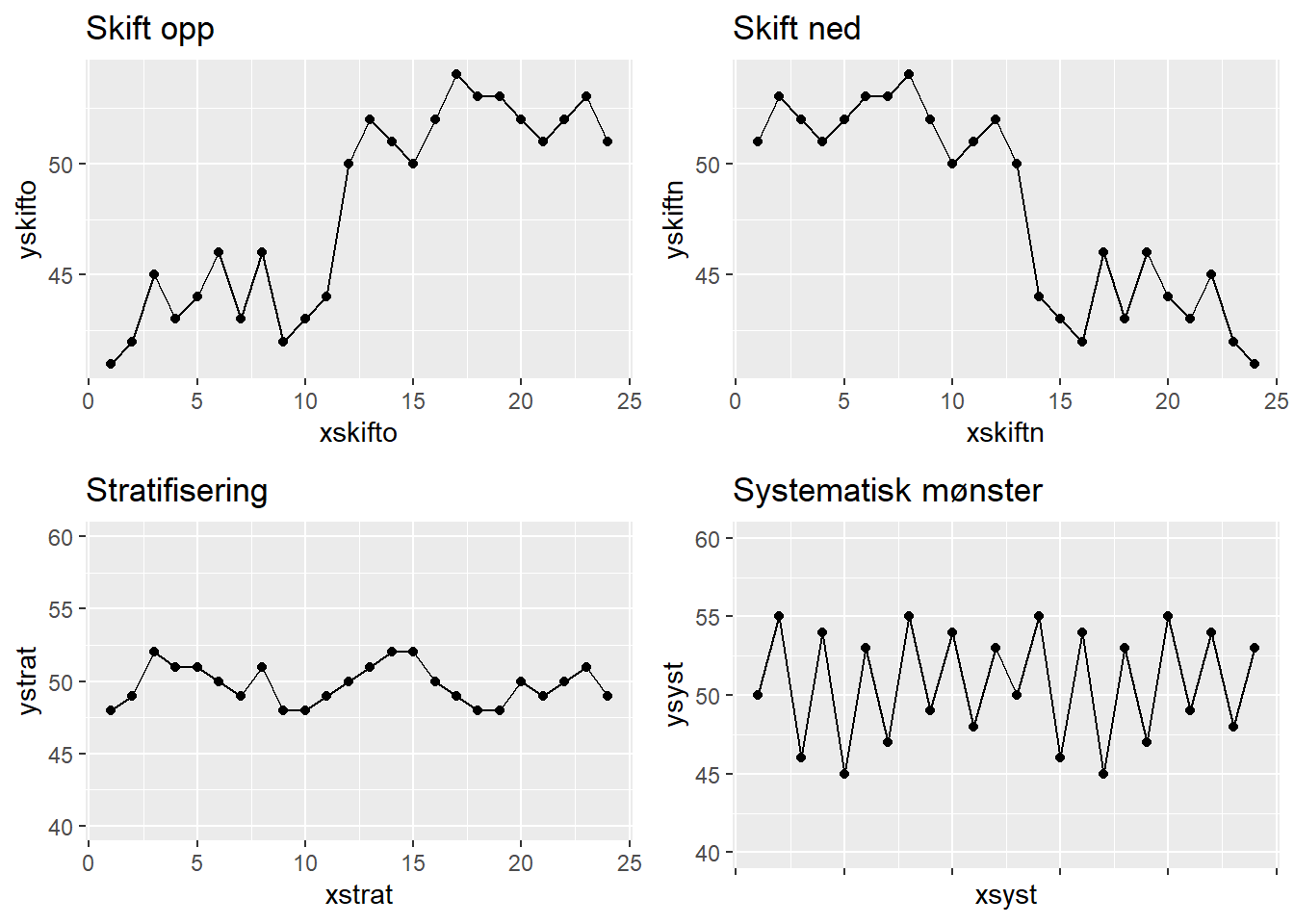
Det eneste mønsteret vi ønsker å knytte noen korte kommentarer til er “stratifisering” som kanskje ikke er helt intuitiv. Stratifisering regnes som en unormal variasjon (“a special cause”) dersom 15 eller flere påfølengde punkter faller innenfor det som kalles sone C (= +/- 1 SD fra snittet). Man sier ofte at punktene “klemmer” senterlinjen, og det kan se ut som prosessen har unormalt liten variasjon. Montgomery (2020) peker på to mulige årsaker: Kontrollgrensene kan være feilkalkulert, eller målingene kan komme fra flere underliggende prosesser. Vi skal ikke gå dypere inn på dette her, men en god gjennomgang av dette er gitt av Rowe (2012) på denne lenken.
7.2 Tolkning av kontrolldiagram
Vi skal være oppmerksom på at de kan opererer med ulike “regler” for når de flagger unormal variasjon. Ulike programmer kan imidlertid ha lagt inn noe ulike regler for hva som betraktes som unormal variasjon. Det er derfor lurt å sette seg inn i hvilke regler som benyttes i det programmet du bruker – alle programmene vil, på en eller annen måte, indikere unormal variasjon hvis vi ber programmet om å gjøre det. Og de fleste programmene vil også la oss velge mellom hvilke kontrollregler vi ønsker å bruke. Her må man altså sjekke opp ut fra hvilket program/R-pakke man ønsker å bruke. I det videre vil vi i hovedsak bruke qcc og qicharts2. Ulike sett regler har vokst fram fra det som regnes som de opprinnelige 4 reglene (1, 2, 5 og 6) (Western Electric Company 1956), til Nelson (1984) 8 regler som er modifisert av flere, blant annet Montgomery (2020) (som qicharts2 bruker).Pakken qcc bruker reglene 1, 2, 3 og 4 som “Shewhart reglene”.
Eksempel på kontrolldiagram med indikasjon på et eller flere brudd på regler for normal variasjon:
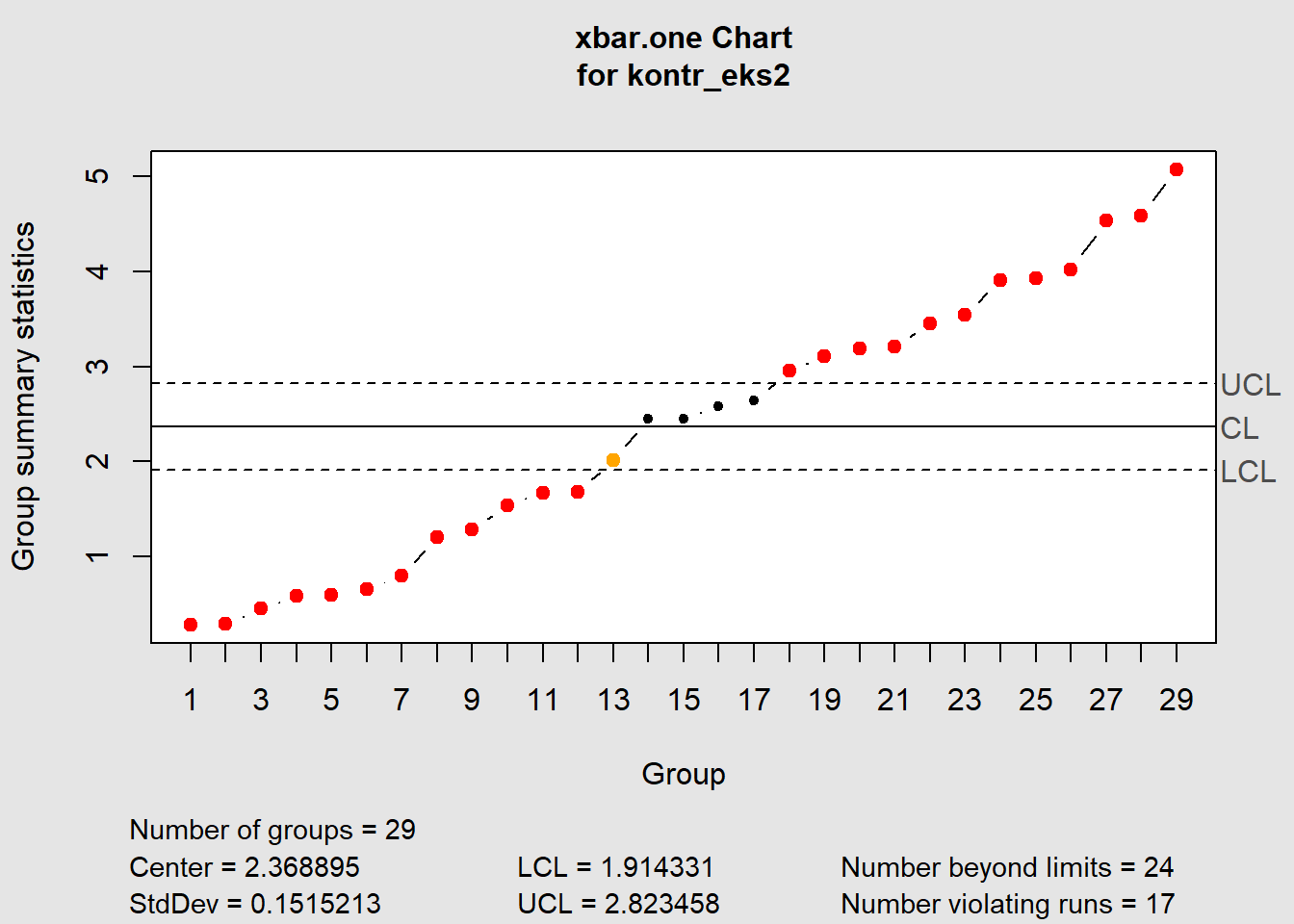
Figure 7.4: Oversikt regler kontrolldiagram
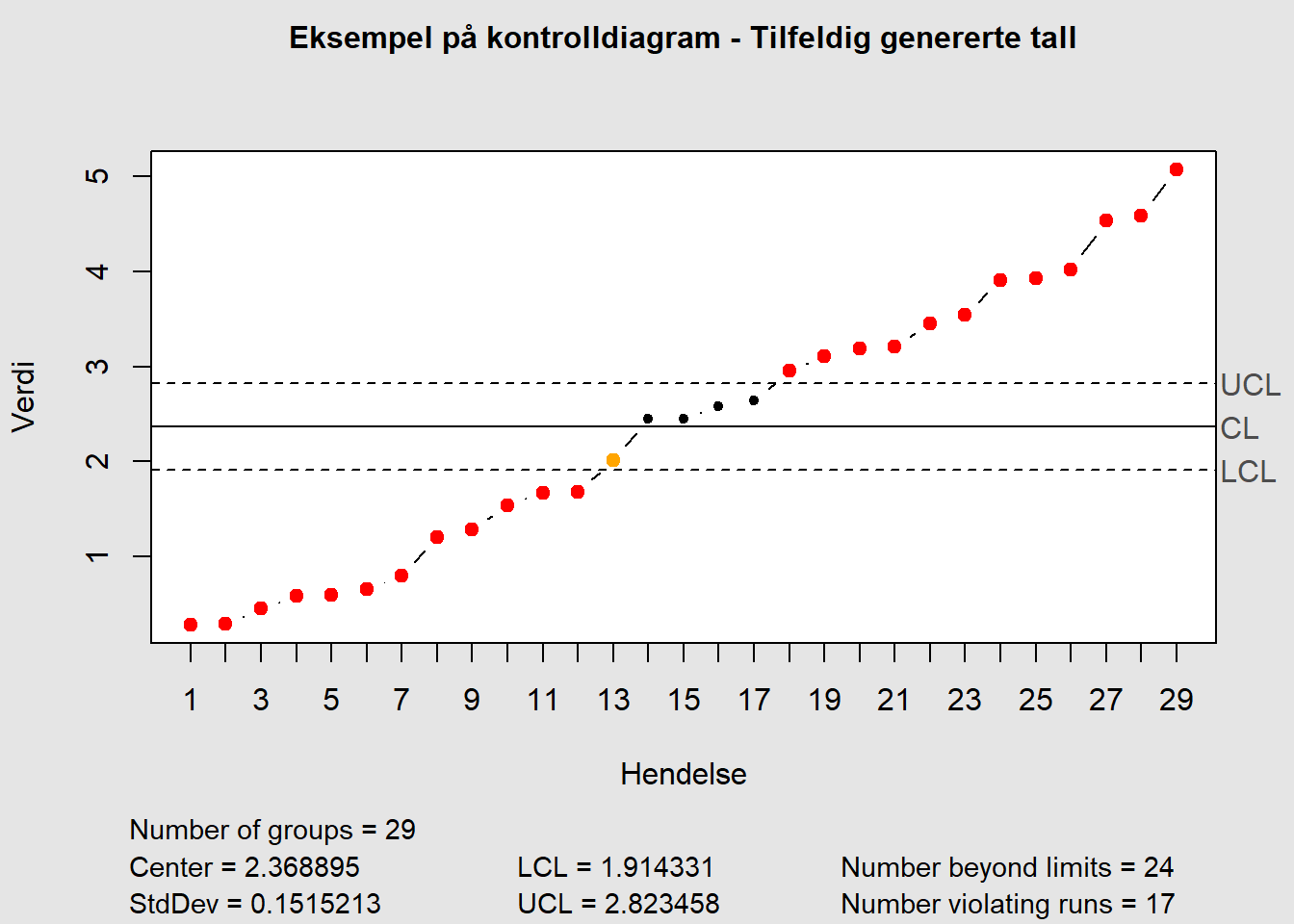
Figure 7.5: Oversikt regler kontrolldiagram
Test | Regel | Indikasjon |
1 | 1 punkt utenfor kontrollgrensene | En større endring |
2 | 2 av 3 påfølgende punkter er mer enn 2 sigma fra gjennomsnittsverdien og i samme retning | En mindre, men vedvarende endring |
3 | 4 av 5 påfølgende punkter er mer enn 1 sigma fra gjennomsnittsverdien og i samme retning | En mindre, men vedvarende endring |
4 | 8 påfølgende punkter er på samme side av gjennomsnittet | Ikke-tilfeldig systematisk variasjon |
5 | 6 påfølgende punkter er i stigende eller synkende trend (etter hverandre) | En middels endring |
6 | 15 påfølgende punkter er innenfor +/- 1 sigma fra gjennomsnittet | En liten endring |
7 | 14 påfølgende punkter alternerer opp og ned (annenhver opp og ned i forhold til foregående verdi) | Stratifisering (at vi egentlig har to eller flere prosesser – et histogram vil f.eks. kunne vise en bimodal distribusjon) |
8 | 8 påfølgende punkter på samme side av gjennomsnittet og ingen innenfor +/- 1 sigma | Blandet variasjon |
Vi skal i det følgende vise reglene grafisk. I diagrammene nedenfor viser vi eksempler på kontrolldiagram inndelt i tilsammen seks soner (A, B og C). Sone C er intervallet +/- 1 sigma fra sentraltendensen, sone B er intervallene +/- 1 til 2 sigma fra sentraltendensen og sone A er intervallene +/- 2 til 3 sigma fra sentraltendensen.
7.2.1 Punkter utenfor kontrollgrensene:
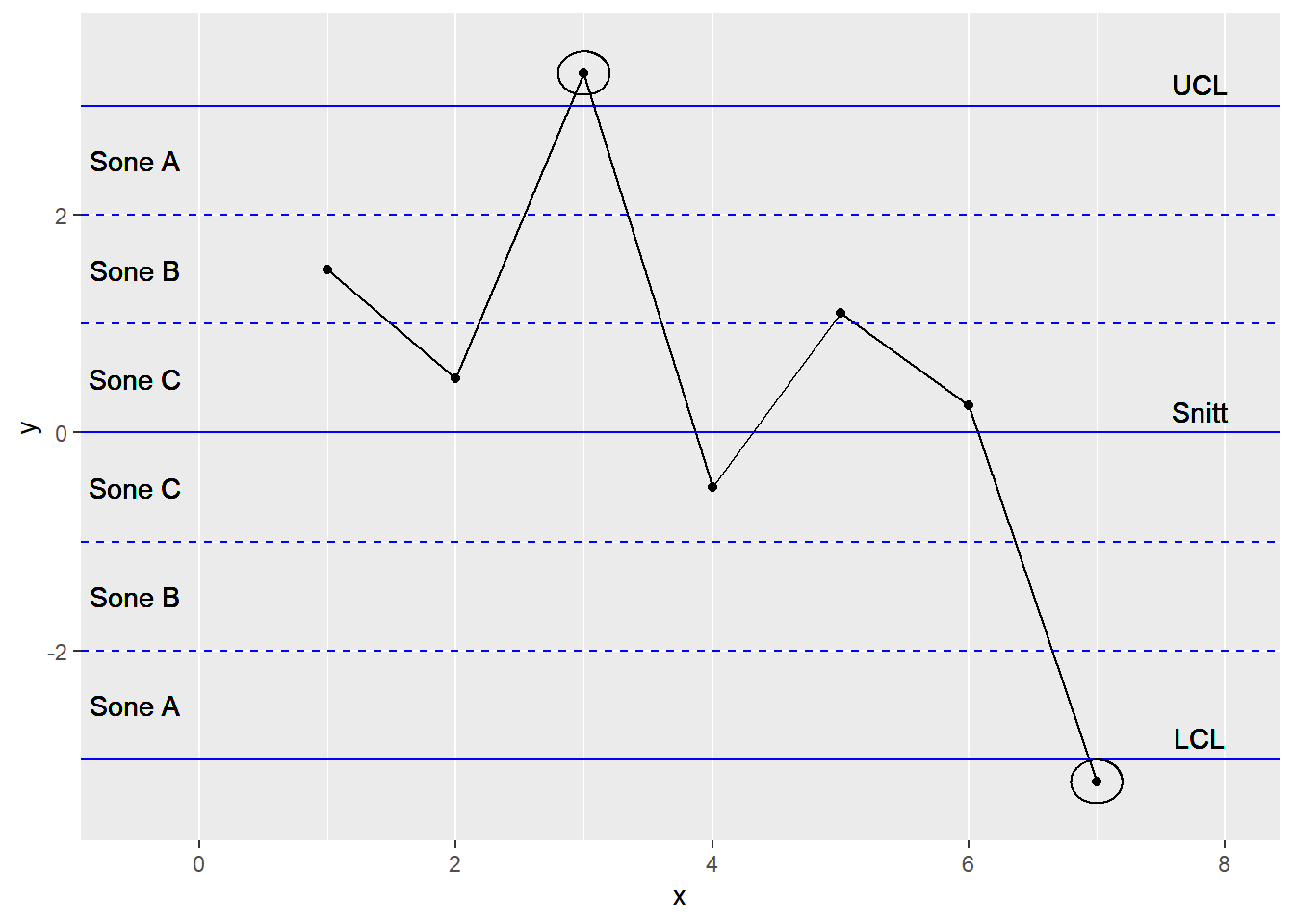
7.2.2 2 av 3 påfølgende punkter er mer enn 2 sigma fra gjennomsnittsverdien (i sone A) og i samme retning
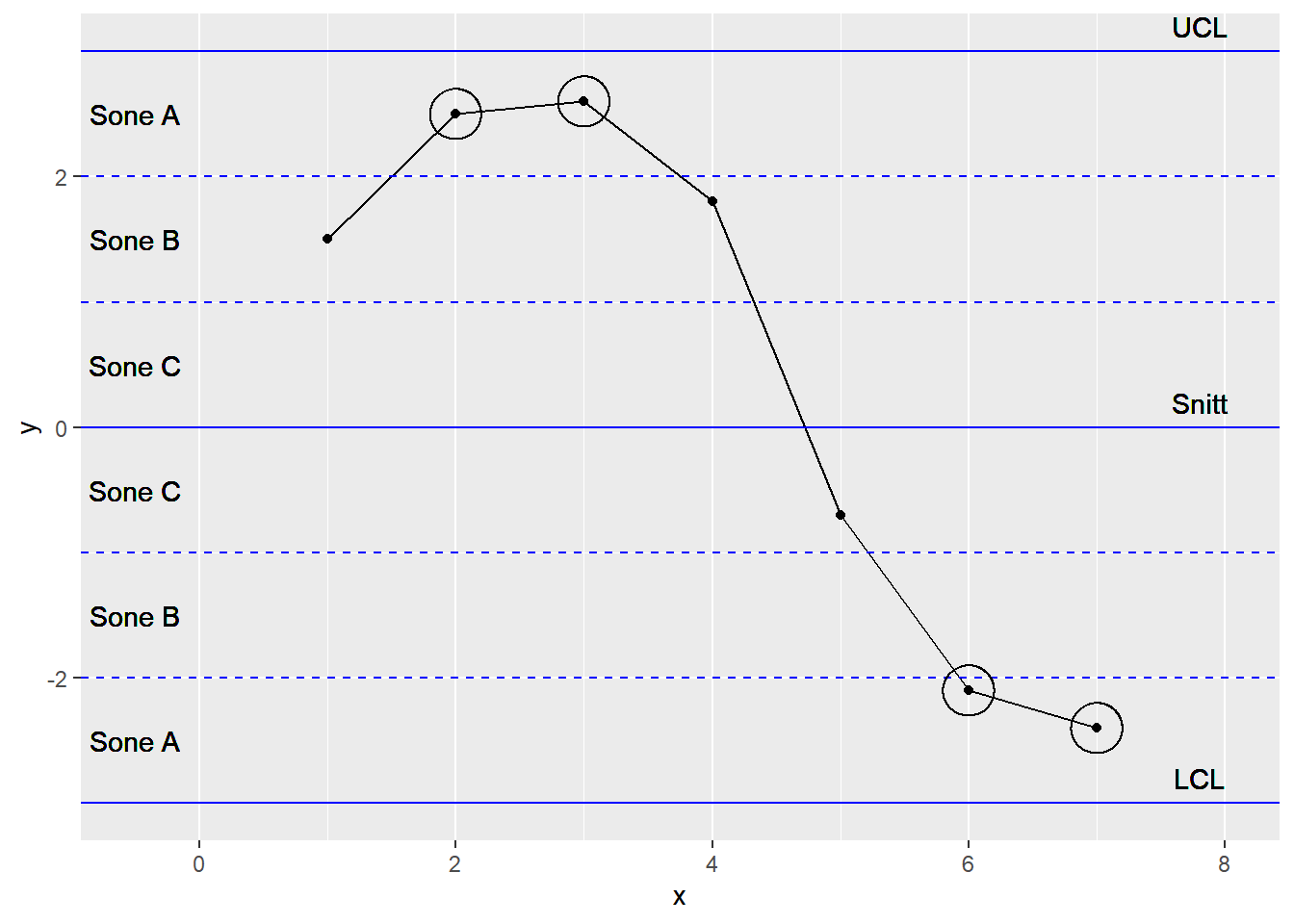
7.2.3 4 av 5 påfølgende punkter er mer enn 1 sigma fra gjennomsnittsverdien (sone A og B) og i samme retning
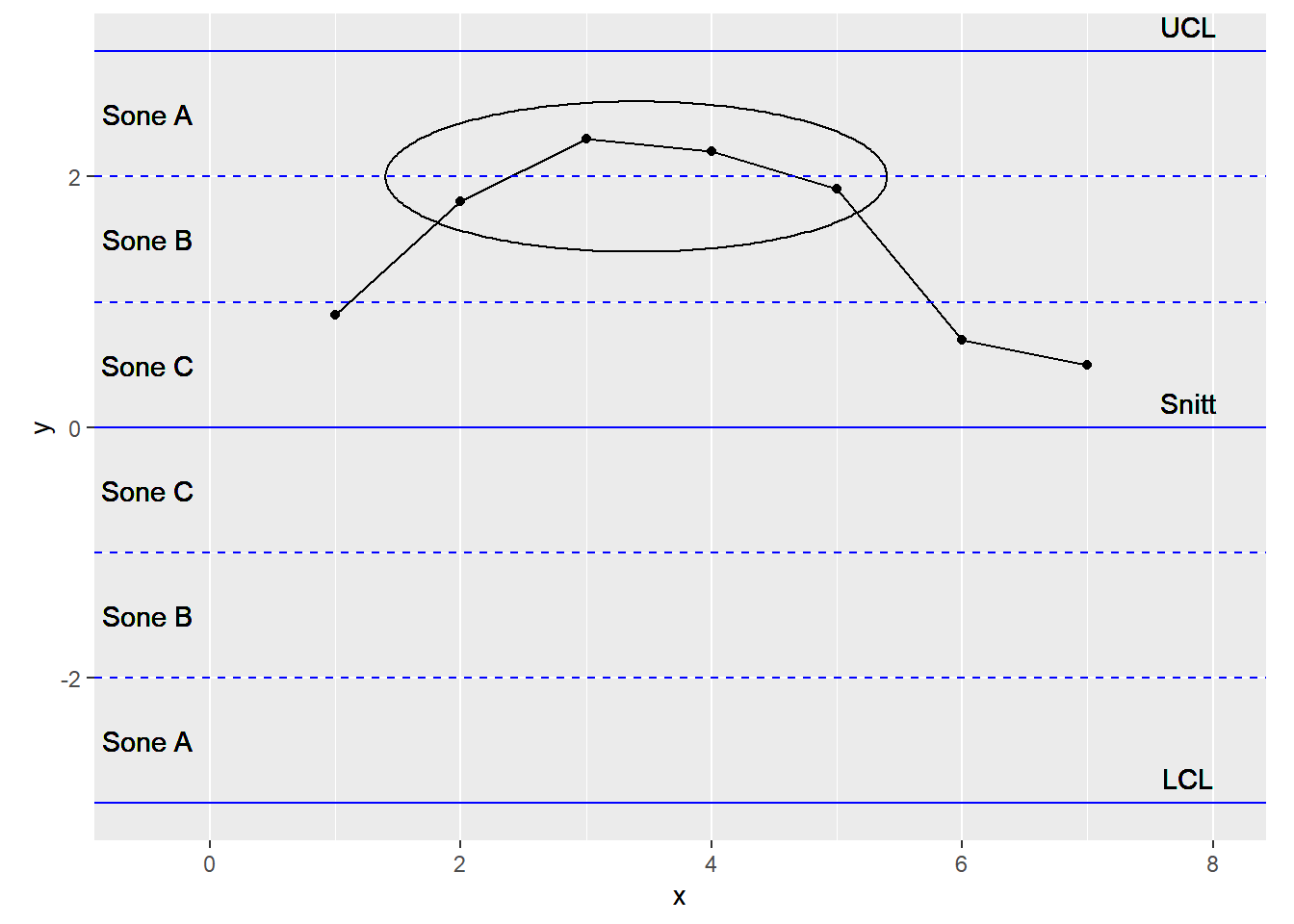
7.2.4 8 påfølgende punkter er på samme side av gjennomsnittet
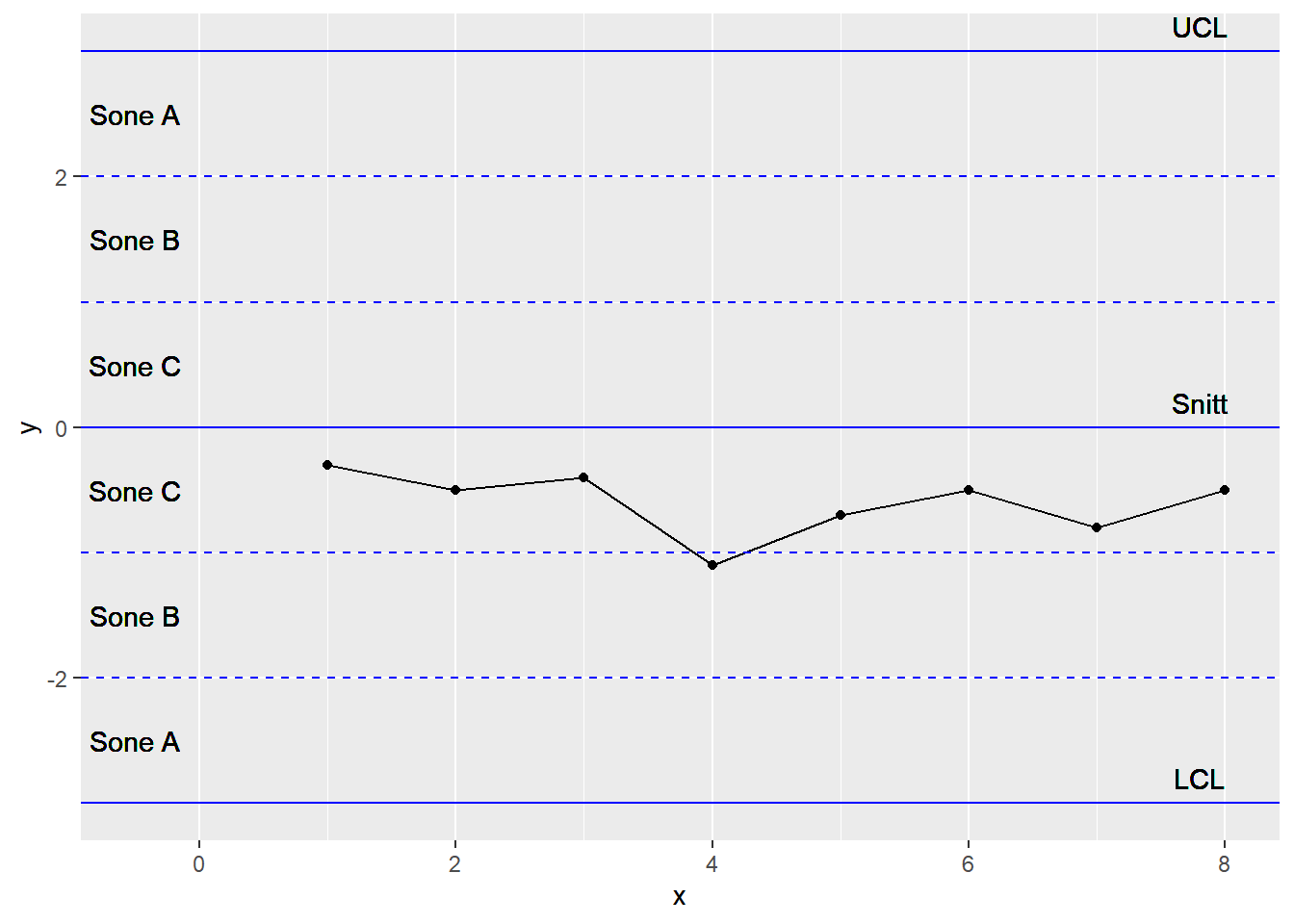
7.2.5 6 påfølgende punkter er i stigende eller synkende trend (etter hverandre)
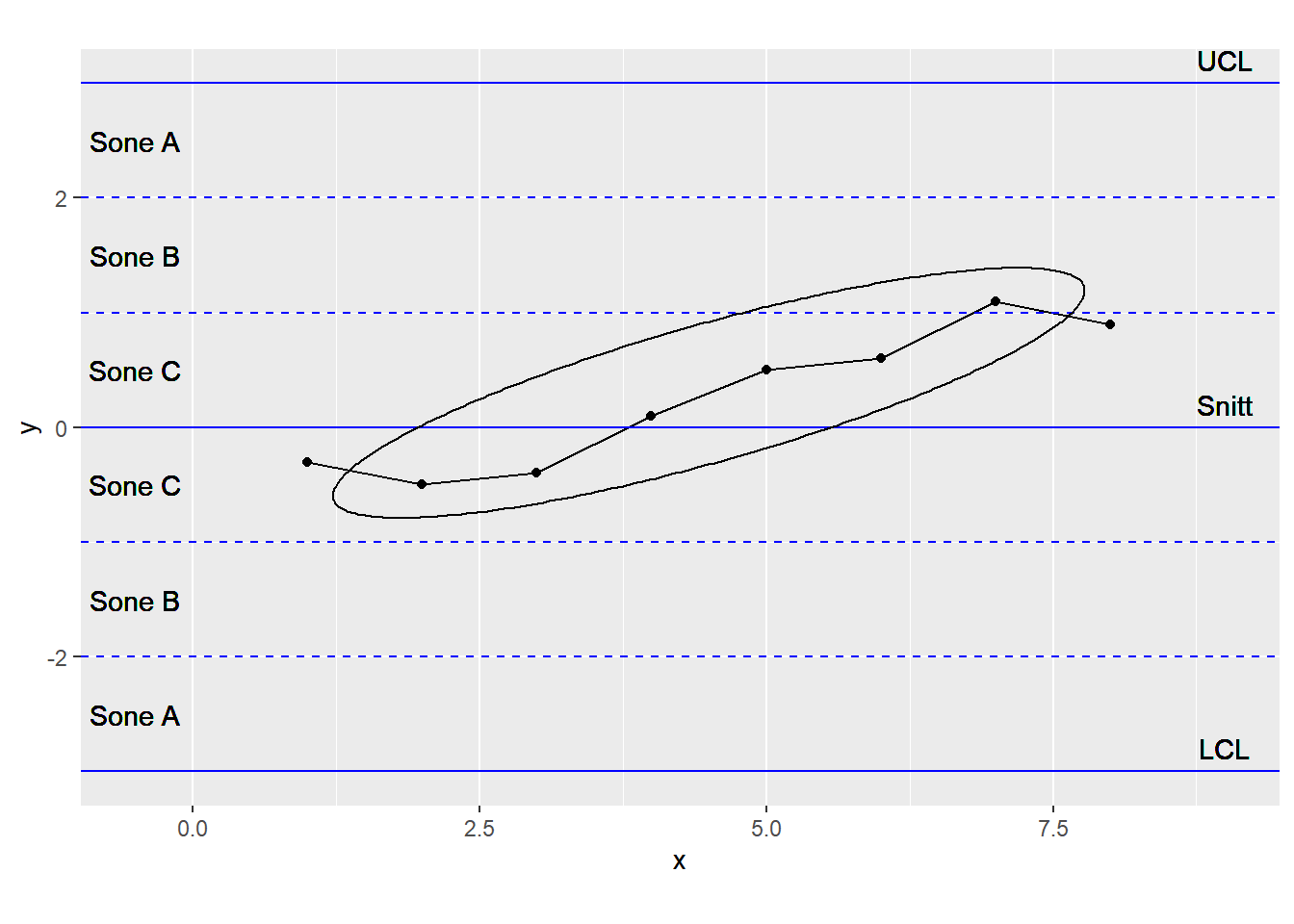
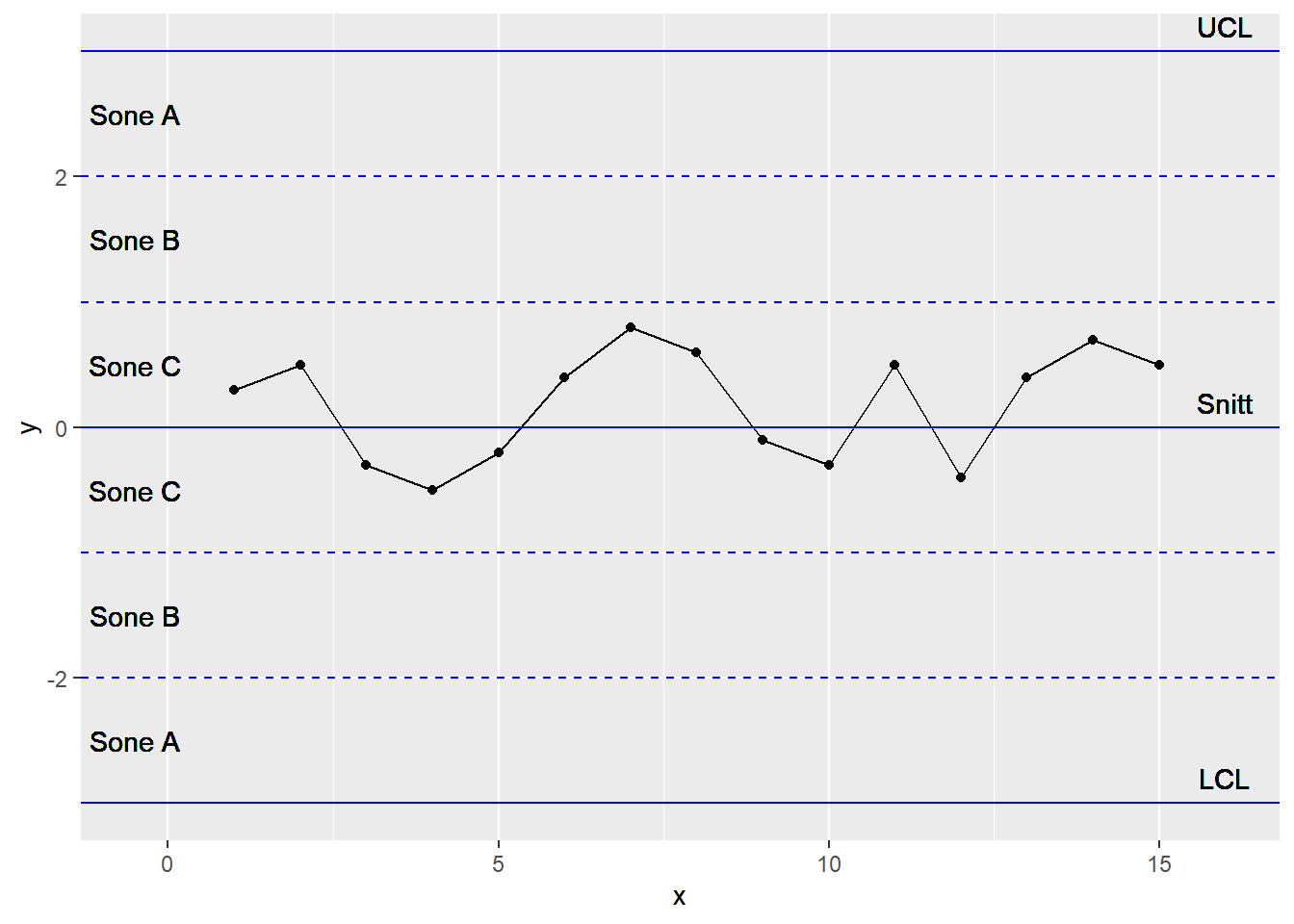
7.2.6 15 påfølgende punkter er innenfor +/- 1 sigma fra gjennomsnittet
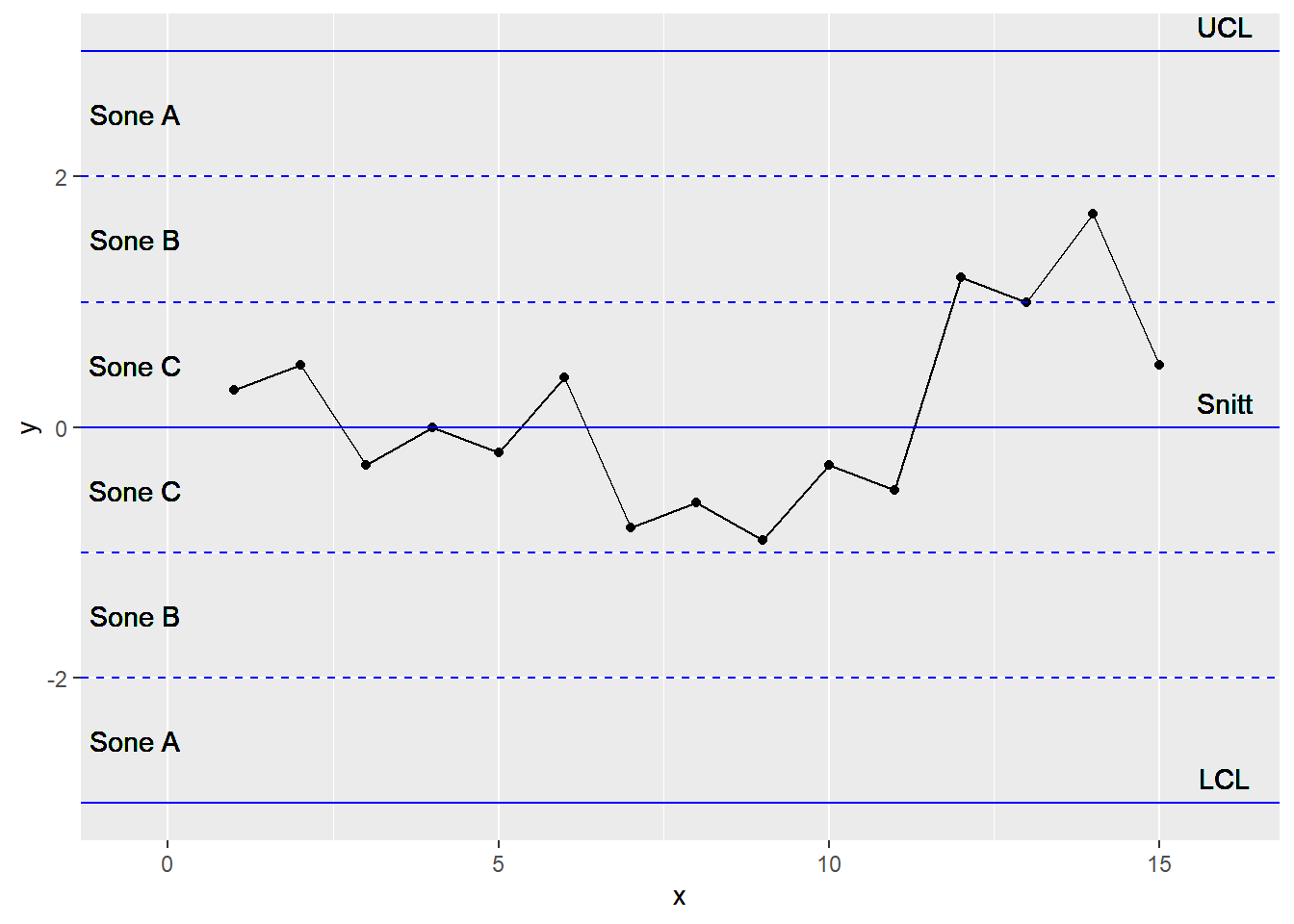
7.2.7 14 påfølgende punkter alternerer opp og ned (annenhver opp og ned i forhold til foregående verdi)
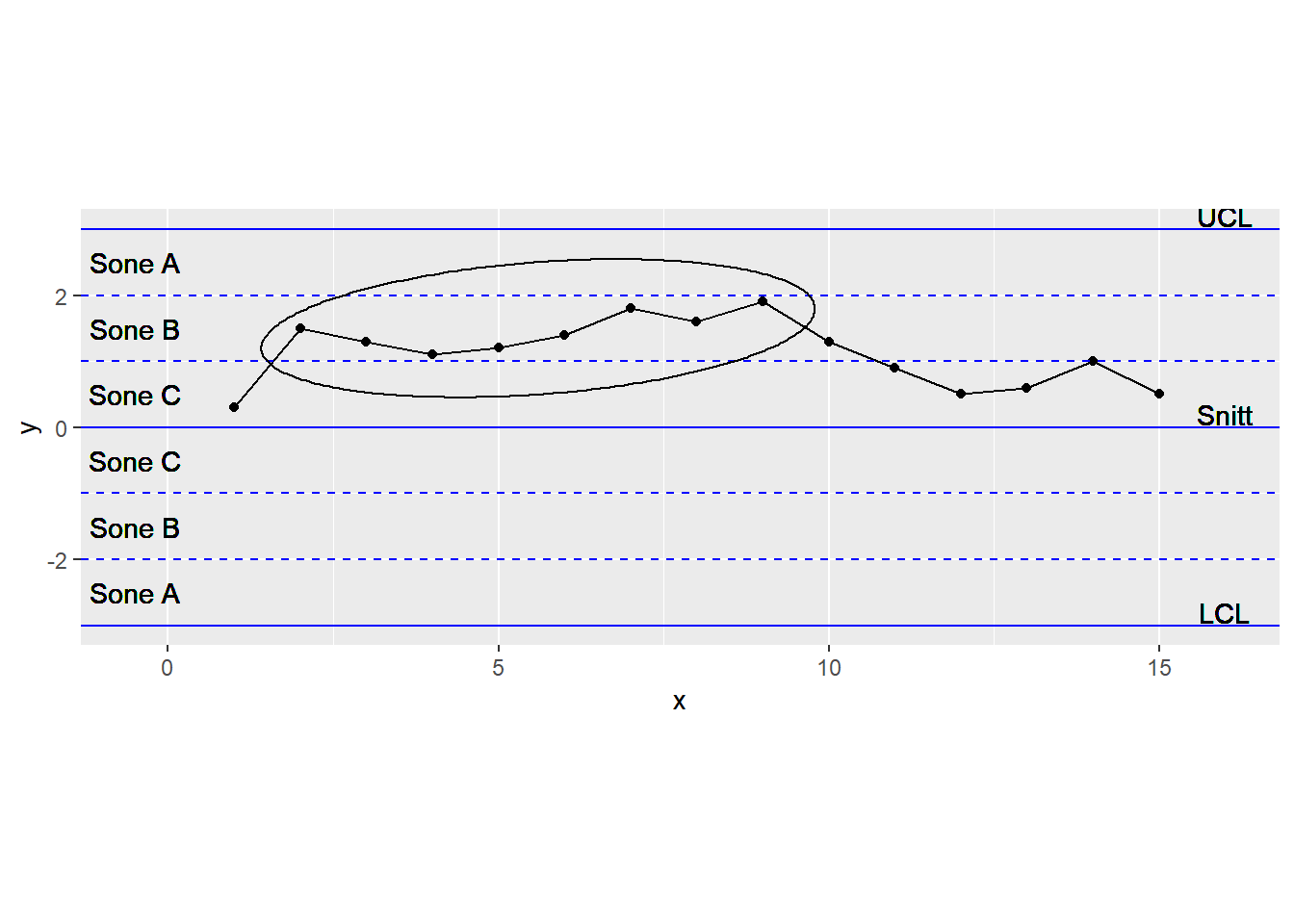
7.2.8 8 påfølgende punkter på samme side av gjennomsnittet og ingen innenfor +/- 1 sigma
Bruk av regel 1 på en normalfordelte data vil kunne gi «falsk alarm» (vise unormal variasjon når det ikke finnes) i 1 av 370 tilfeller i gjennomsnitt. Hvis man imidlertid legger til testene 2, 5 og 6 stiger raten av feil alarmer til 1 av 91,75 tilfeller. Et godt råd som ofte gis er å velge tester før man lage kontrolldiagrammene basert på kjennskap til prosessen man holder på med. Som Anhøj (2021a) påpeker: “It is a common misunderstanding that control charts are superior to run charts. The confusion may stem from the fact that different sets of rules for identifying non-random variation in run charts are available, and that these sets differ significantly in their diagnostic properties.”
Vi skal i videre i dette kapittelet ta for oss ulike typer kontrolldiagrammene (ref. flytskjema for valg av kontrolldiagram). Vi vil vise et eksempel på hvert av de vanlige kontrolldiagrammene. For hvert eksempel finnes det en Excelfil med dataene som er brukt for de ulike eksemplene og en video som viser framgangsmåten i Excel. Grunnen til dette er at for mange vil Excel være et mye mer kjent grensesnitt enn R. Samtidig, ved å se på videoen og stegene som gjøres, ser man hvordan det enkelte kontrolldiagram er bygd opp. Selvsagt er dette mye mer tidkrevende enn å bare kjøre analysen i R, men det kan gi en fin innsikt i “hva som egentlig skjer”. På sikt mener vi det er mye å hente på å bruke R og pakken qicharts2 eller pakken qcc. Alternativt kan man investere i et tillegg til Excel som nevnt i kapittel 1.
7.3 Telledata (attributter)
Diagrammene i dette delkapittelet handler om data der vi kan telle og putte dataene inn i kategorier. Motsetningen er måledata som er kontinuerlige data som behandles i neste delkapittel.
7.3.1 p-diagram
P-diagrammet er trolig det mest brukte diagrammet i helsesektoren (Anhøj 2021a). Her er dataene binomiale, dvs type ja/nei. Vi kan f.eks. registrere om det er eller ikke er et avvik fra en gitt rutine. P-diagrammet og NP-diagrammet skiller seg kun fra hverandre ved at NP-diagrammet forutsetter en lik størrelse på utvalget hver måling, mens P-diagrammet brukes når utvalgsstørrelsen varierer. Hvis vi f.eks. registrerer antall avvik i en rutine pr uke og antallet gjennomføringer av rutinen varierer fra uke til uke bør vi bruke et P-diagram.
La oss tenke oss at vi har følgende data som viser antall keisersnitt og totalt antall fødsler på et sykehus (eksempeldata modifisert fra QIMacros 2021).
År 1 | År 2 | ||||
Måned | Keisersnitt | Fødsler | Måned. | Keisersnitt. | Fødsler. |
Jan | 65 | 370 | Jan | 62 | 374 |
Feb | 64 | 383 | Feb | 48 | 355 |
Mar | 77 | 446 | Mar | 57 | 393 |
Apr | 59 | 454 | Apr | 64 | 417 |
Mai | 64 | 463 | Mai | 66 | 434 |
Jun | 74 | 431 | Jun | 55 | 421 |
Jul | 72 | 443 | Jul | 51 | 417 |
Aug | 67 | 451 | Aug | 82 | 444 |
Sep | 59 | 433 | Sep | 65 | 429 |
Okt | 65 | 407 | Okt | 69 | 411 |
Nov | 60 | 381 | Nov | 62 | 386 |
Des | 68 | 406 | Des | 66 | 357 |
Datasettet i Excelformat finner du her:
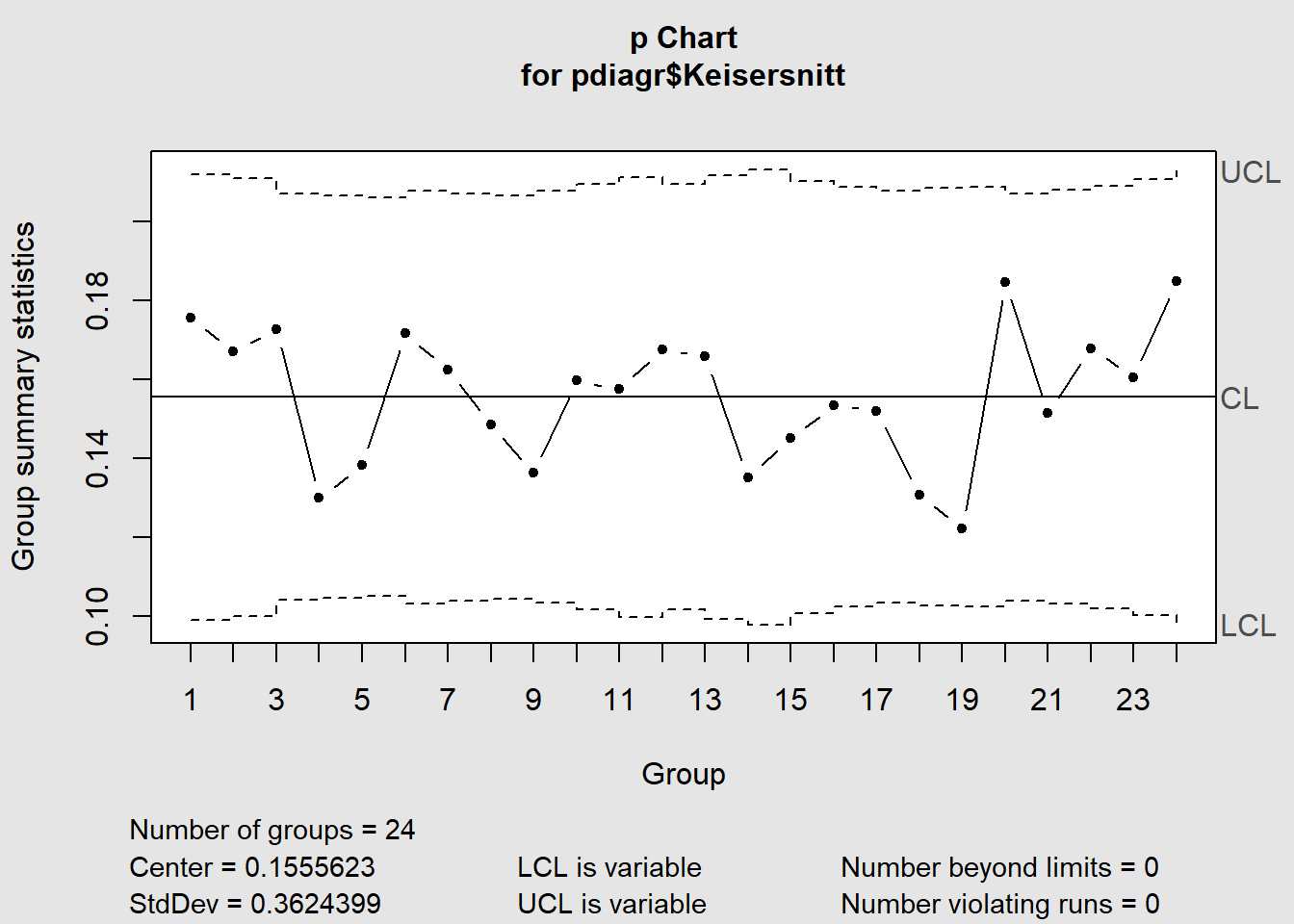
Figure 7.6: p-diagram
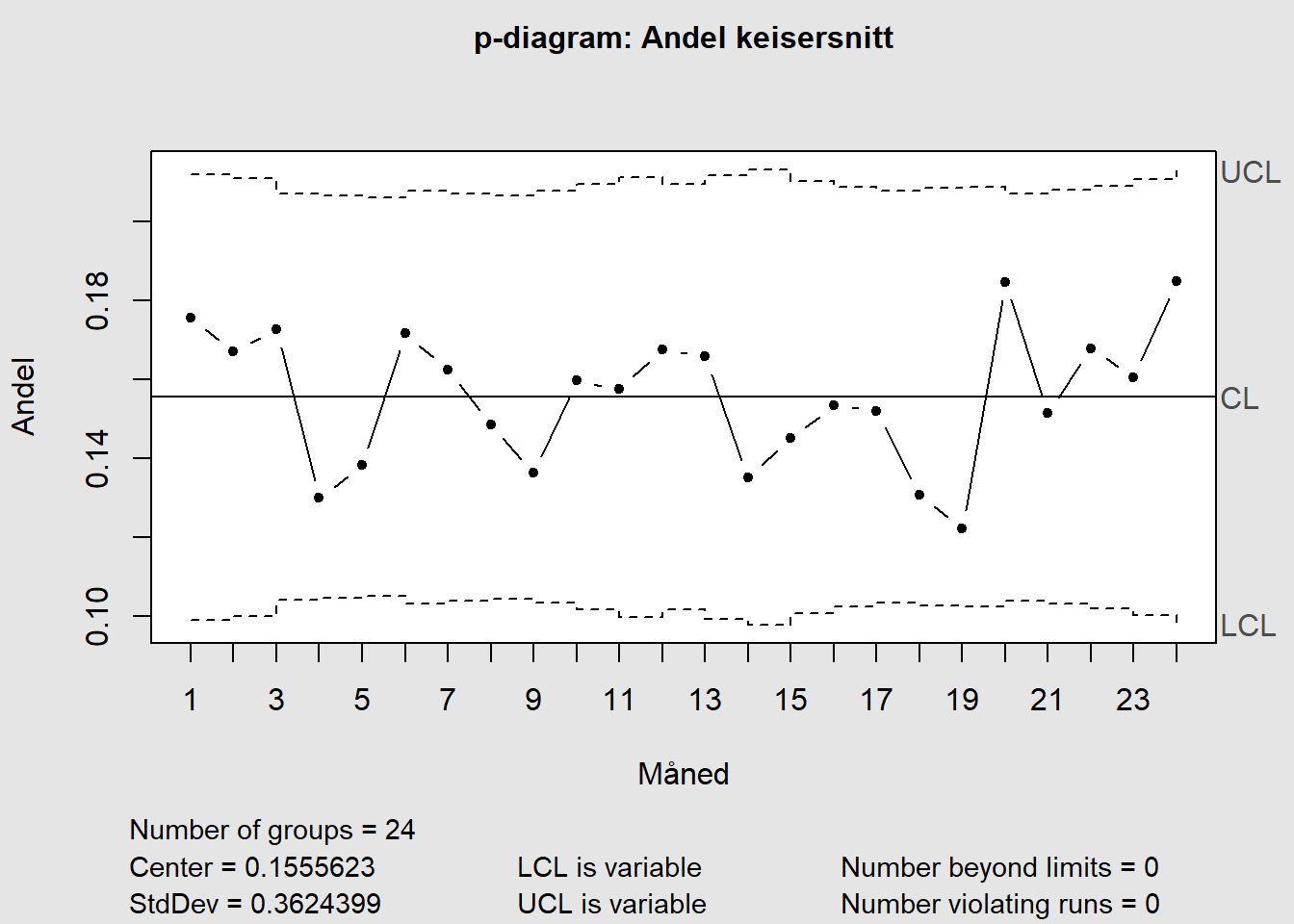
Figure 7.7: p-diagram
I p-diagrammet vil UCL og LCL variere noe siden det tas hensyn til at n varierer fra registrering til registrering.
Video med framgangsmåte i Excel ligger her.
7.3.2 Laney’s p-diagram
I noen tilfeller har vi data som gir svært smale kontrollgrenser (eksempeldata modifisert fra SPC for Excel 2021).
La oss anta følgende datasett:
Måned | Medlemmer | Pr_telefon | Måned. | Medlemmer. | Pr_telefon. |
Jan07 | 8755 | 3852 | Sep07 | 21600 | 9250 |
Feb07 | 9800 | 4100 | Okt07 | 20500 | 9950 |
Mar07 | 17000 | 7083 | Nov07 | 18700 | 9846 |
Apr07 | 16400 | 7339 | Des07 | 18900 | 9854 |
Mai07 | 19500 | 9406 | Jan08 | 14300 | 8034 |
Jun07 | 19800 | 9310 | Feb08 | 14800 | 8162 |
Jul07 | 21200 | 7250 | Mar08 | 14500 | 8122 |
Aug07 | 22300 | 10400 | Apr08 | 14600 | 8200 |
Datasett: Download Laneyp.xlsx
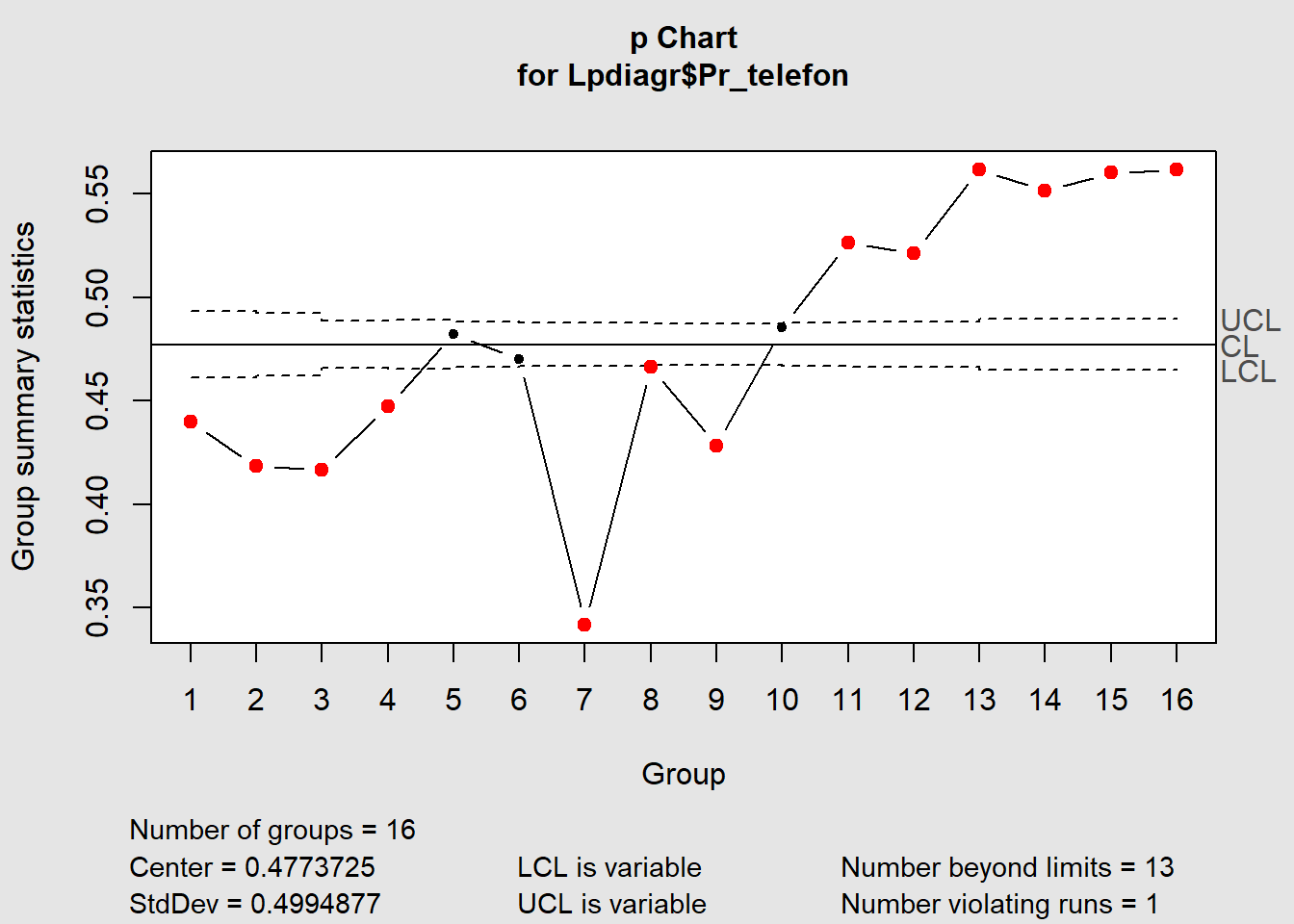
Figure 7.8: p-diagram for Laney
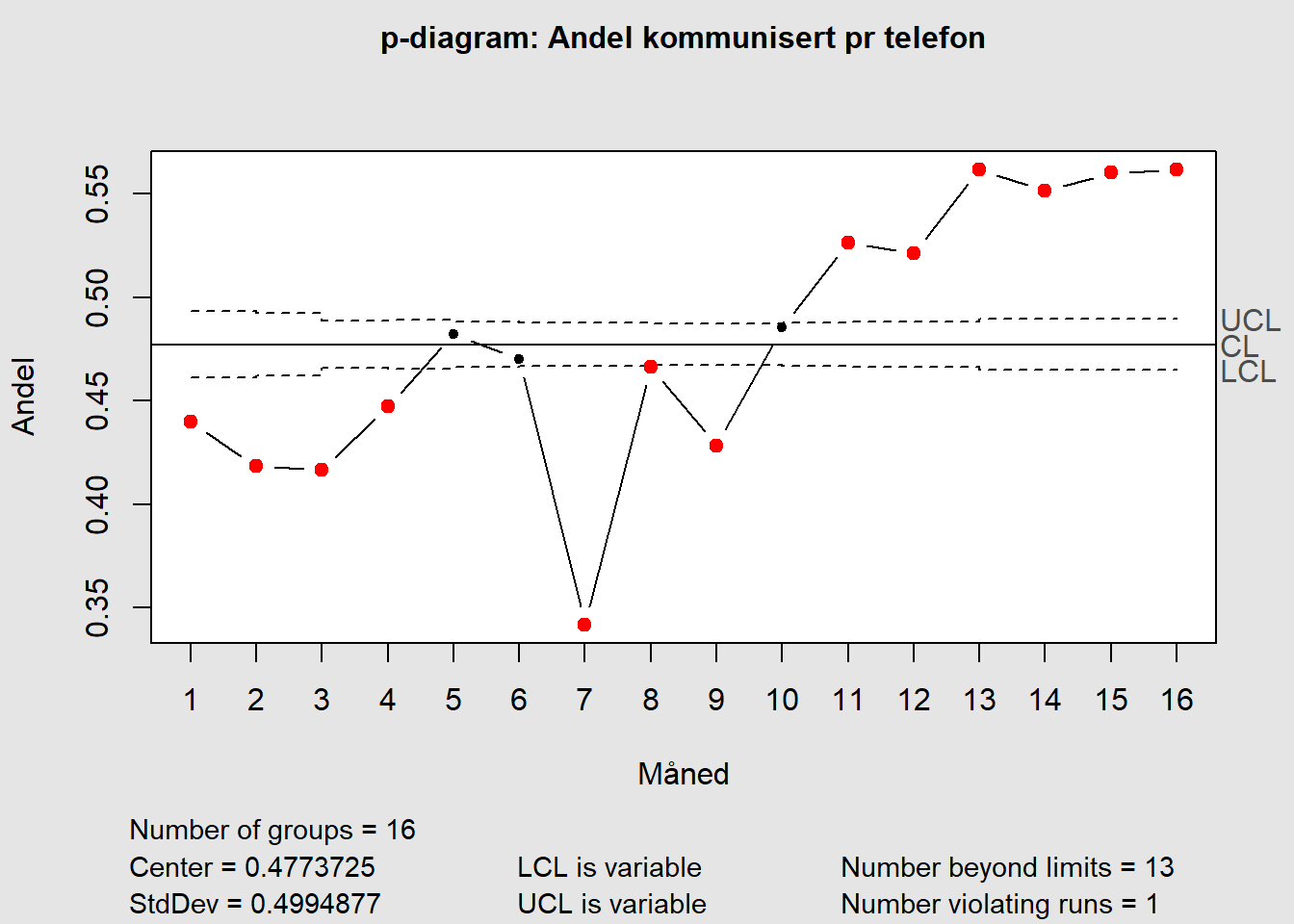
Figure 7.9: p-diagram for Laney
Diagrammet gir liten mening når mer eller mindre alle punktene ligger utenfor kontrollgrensene. Laney (2002) peker på at p- og u-diagrammer har forutsetninger om distribusjonen som blant annet antar at gjennomsnittet er konstant over tid. Kombinert med veldig stor utvalgsstørrelse gir dette såkalt overdispersjon, hvilket betyr at den faktiske variansen er større enn det modellen benytter. Framgangsmåten Laney foreslår kan virke noe teknisk, men innebærer å regne ut z verdien for alle punktene (z verdien forteller antallet standardavvik mellom det målte punktet og gjennomsnittet). Z-verdiene brukes så for å regne ut Moving Range (MR), som igjen brukes til å regne ut gjennomsnittlige MR, som igjen brukes til å regne ut UCL og LCL.
Vi har laget en video som kort forklarer begrepet Moving Range.
Som dere vil se i videoen (se lenke litt lenger ned) er den eneste forskjellen i formlene som regner ut UCL og LCL et uttrykk for standardavviket for z-verdiene. Denne, sier Laney, korrigerer for den relative andelen av prosessvariasjon som ikke forklares av den binomiale fordelingen alene. Ved stor n minskes variasjonen fra utvalgene.
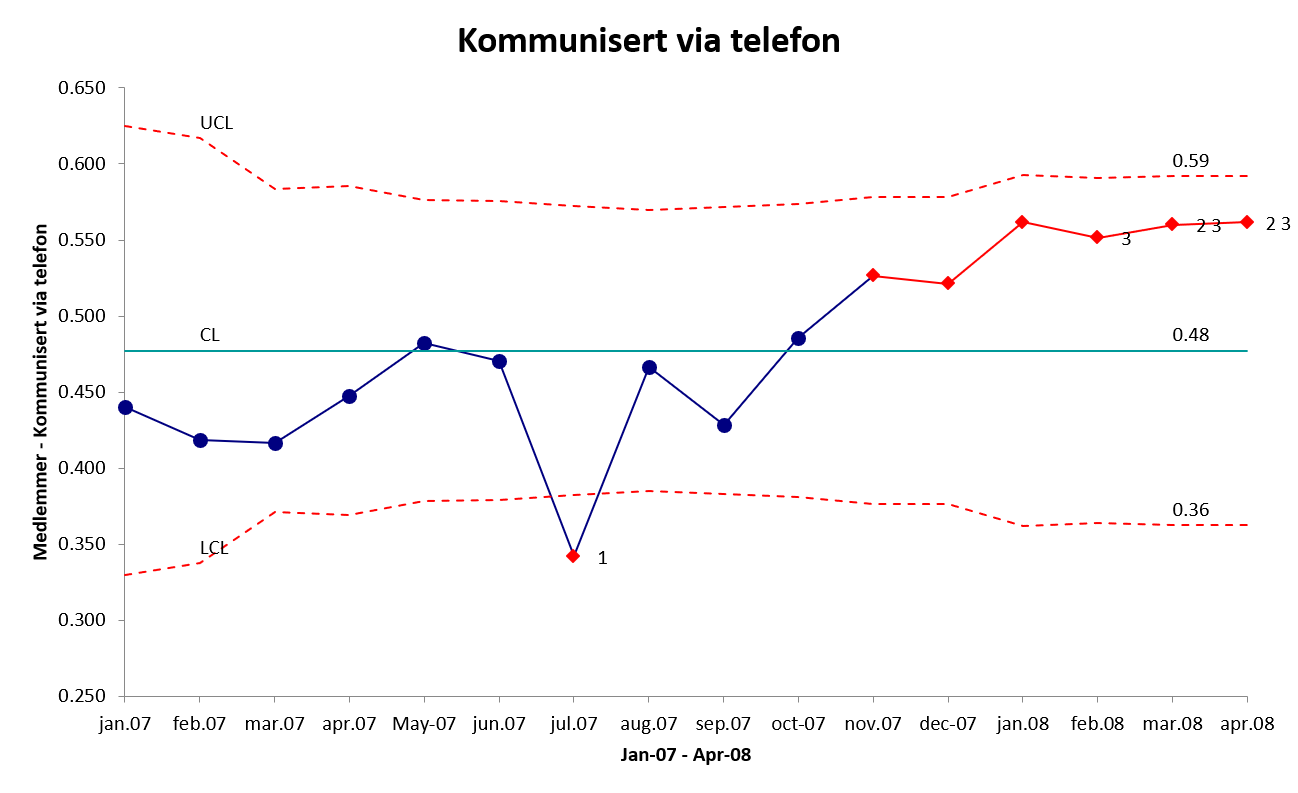
Laneys p’-diagram er i realiteten veldig likt et I-diagram, med den forskjellen at p’-diagrammet tar høyde for varierende utvalgsstørrelser. Du finner en video som forklarer framgangsmåten i Excel her.
7.3.3 np-diagram
Forskjellen på p-diagram og np-diagram ligger i om utvalgsstørrelsen er lik eller ulik gjennom registreringene. I dette eksempelet sjekker vi om en prosedyre er korrekt gjennomført eller ikke. For å registrere dette tar vi hver uke 50 stikkprøver og registrerer hvor mange som ikke er gjennomført iht prosedyren (eksempeldata modifisert fra QIMacros 2021).
Uke | n | Feil | Uke. | n. | Feil. |
1 | 50 | 12 | 13 | 50 | 17 |
2 | 50 | 15 | 14 | 50 | 12 |
3 | 50 | 8 | 15 | 50 | 22 |
4 | 50 | 10 | 16 | 50 | 8 |
5 | 50 | 4 | 17 | 50 | 10 |
6 | 50 | 7 | 18 | 50 | 5 |
7 | 50 | 16 | 19 | 50 | 13 |
8 | 50 | 9 | 20 | 50 | 11 |
9 | 50 | 14 | 21 | 50 | 20 |
10 | 50 | 10 | 22 | 50 | 18 |
11 | 50 | 5 | 23 | 50 | 24 |
12 | 50 | 6 | 24 | 50 | 15 |
Datasett: Download np_diagram.xlsx
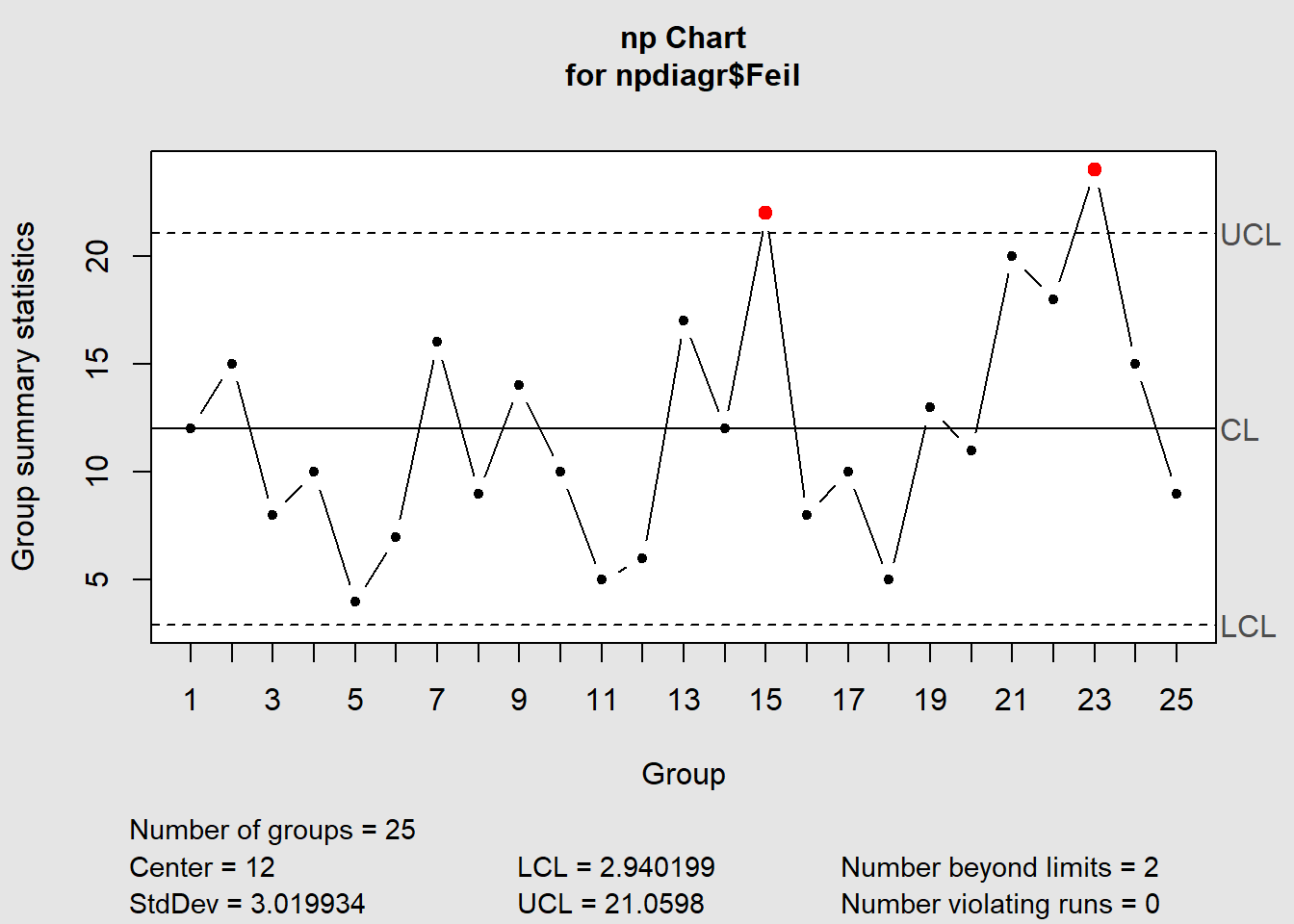
Figure 7.10: np-diagram
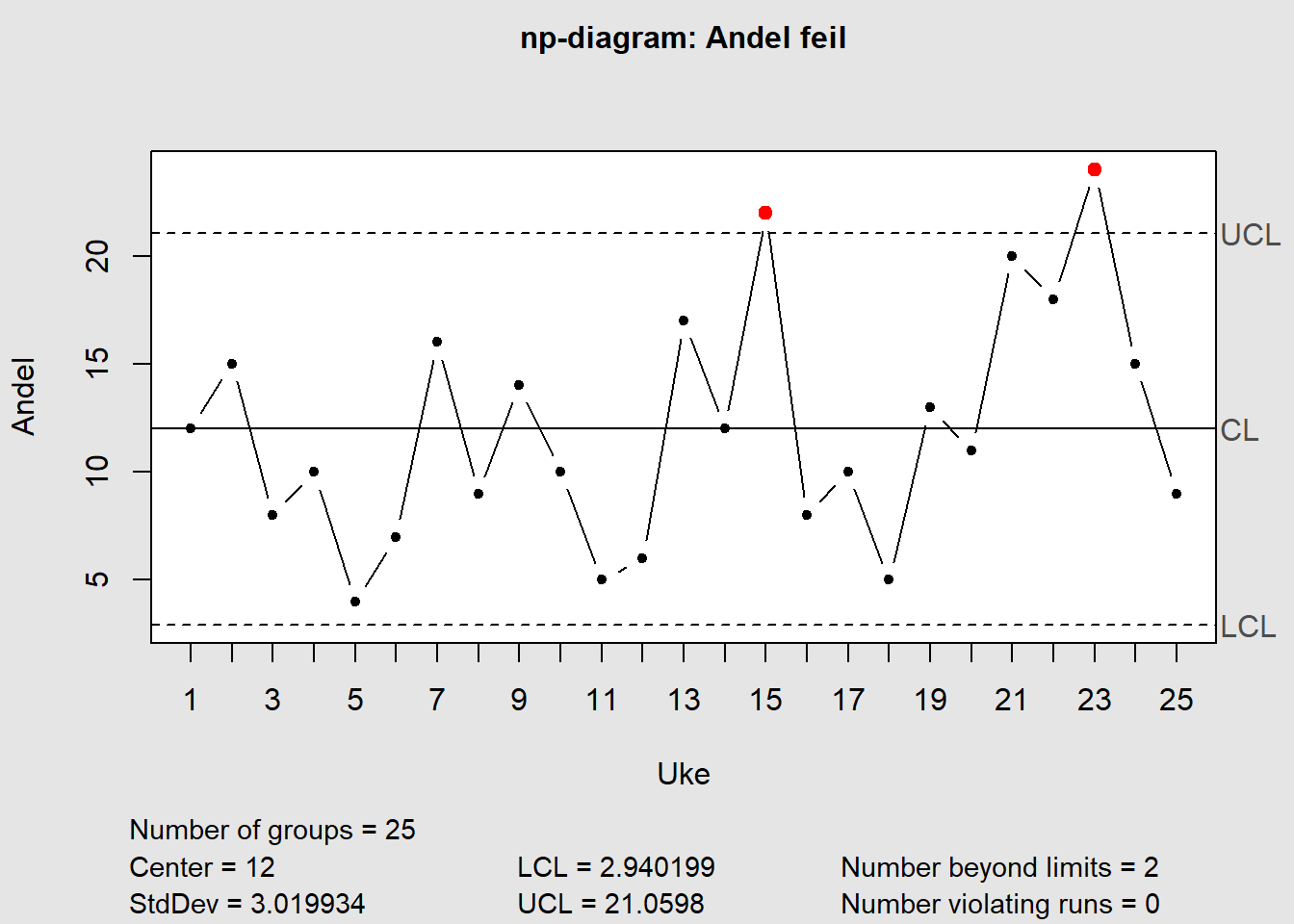
Figure 7.11: np-diagram
I dette tilfellet ser vi at det ved to anledninger – uke 15 og 23 – var brudd på regel 1 (utenfor 3 sigma).
Som vanlig finnes det en Excelvideo som viser framgangsmåten steg-for-steg i Excel.
7.3.4 u-diagram
p- og np-diagrammer teller antall defekter – en hendelse, et produkt, en tjeneste er enten defekt eller ikke. Men i mange tilfeller gir det ikke så mye mening å se på defekt/ikke-defekt. En bil kan f.eks. ha flere feil, men likevel være kjørbar. Bilen er ikke defekt selv om den har feil vi er interessert i. Det vi i stedet kan være mer interessert i er hvor mange feil har enheten vi ser på. Vi kan f.eks. være interessert i hvor mange kundeklager som har kommet inn i en periode. Vi er da interessert i antallet klager og antar ikke at hele prosessen er defekt selv om vi har klager.
I eksempelet under ser vi på antall pasientfall opp mot totalt antall pasientdager (eksempeldata modifisert fra QIMacros 2021).
Måned | Pasientfall | Pasientdager | Måned. | Pasientfall.. | Pasientdager. |
Jun | 17 | 4658 | Jun | 42 | 5609 |
Jul | 22 | 4909 | Jul | 41 | 5722 |
Aug | 23 | 4886 | Aug | 24 | 5261 |
Sep | 30 | 4970 | Sep | 22 | 6071 |
Okt | 28 | 4780 | Okt | 50 | 6072 |
Nov | 18 | 4973 | Nov | 51 | 5335 |
Des | 44 | 5762 | Des | 39 | 6483 |
Jan | 42 | 5441 | Jan | 22 | 5752 |
Feb | 33 | 5893 | Feb | 31 | 5731 |
Mar | 33 | 5743 | Mar | 33 | 5017 |
Apr | 33 | 4747 | Apr | 25 | 5158 |
Mai | 27 | 5118 | Mai | 22 | 5040 |
Datasett: Download u_diagram.xlsx
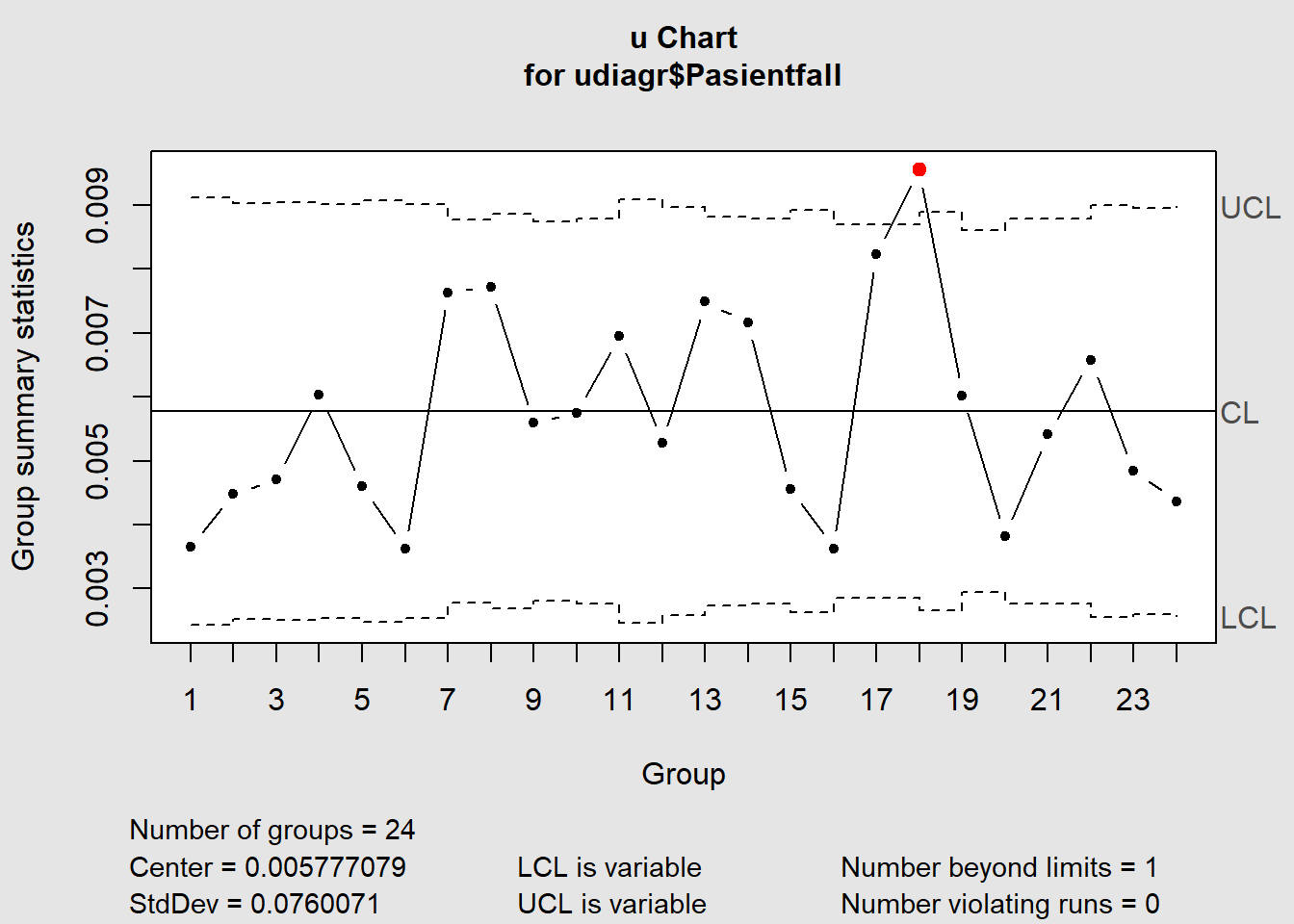
Figure 7.12: u-diagram
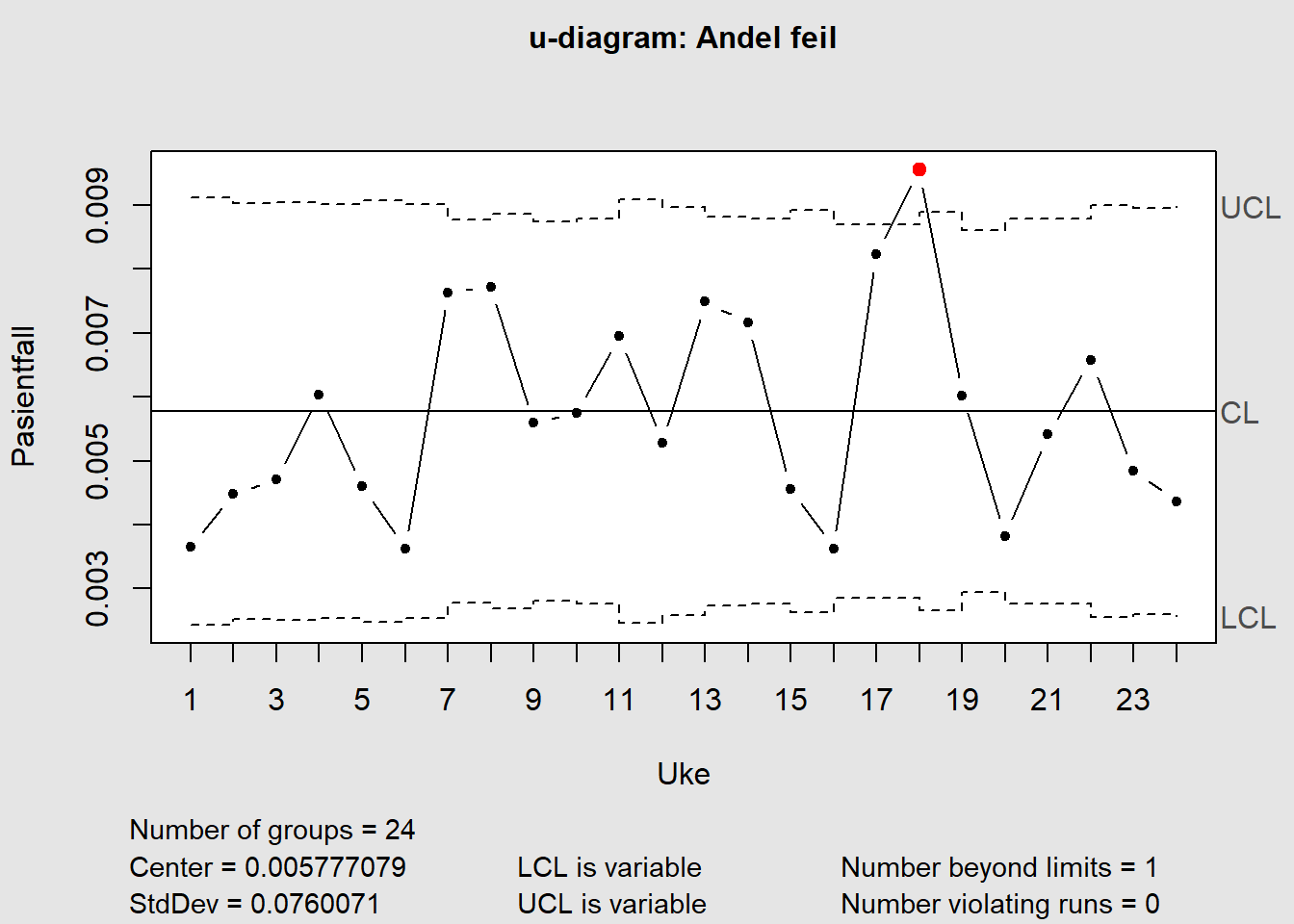
Figure 7.13: u-diagram
Video her for Excel
7.3.5 Laney’s u-diagram
Som for p-diagrammet finnes det et alternativ fra Laney (2002). Se punktet om Laneys p’-diagram – samme forhold som ble diskutert for p vs p’-diagram gjelder for u vs u’-diagram.
Datasett: Download ludiagram.xlsx
Data (eksempeldata modifisert fra SPC for Excel 2021).
Uke | Pasienter | Feil | Uke. | Pasienter. | Feil. |
1 | 6566 | 98 | 14 | 6598 | 107 |
2 | 9671 | 36 | 15 | 10029 | 43 |
3 | 8129 | 104 | 16 | 8192 | 50 |
4 | 7757 | 90 | 17 | 9417 | 102 |
5 | 7880 | 53 | 18 | 7130 | 63 |
6 | 9102 | 93 | 19 | 5455 | 58 |
7 | 7201 | 180 | 20 | 5946 | 52 |
8 | 7940 | 51 | 21 | 10222 | 99 |
9 | 8486 | 64 | 22 | 8154 | 43 |
10 | 9858 | 116 | 23 | 5114 | 46 |
11 | 9226 | 91 | 24 | 6256 | 87 |
12 | 10496 | 69 | 25 | 6466 | 84 |
13 | 9427 | 43 |
Uten Laneys korreksjon (standard u-diagram):
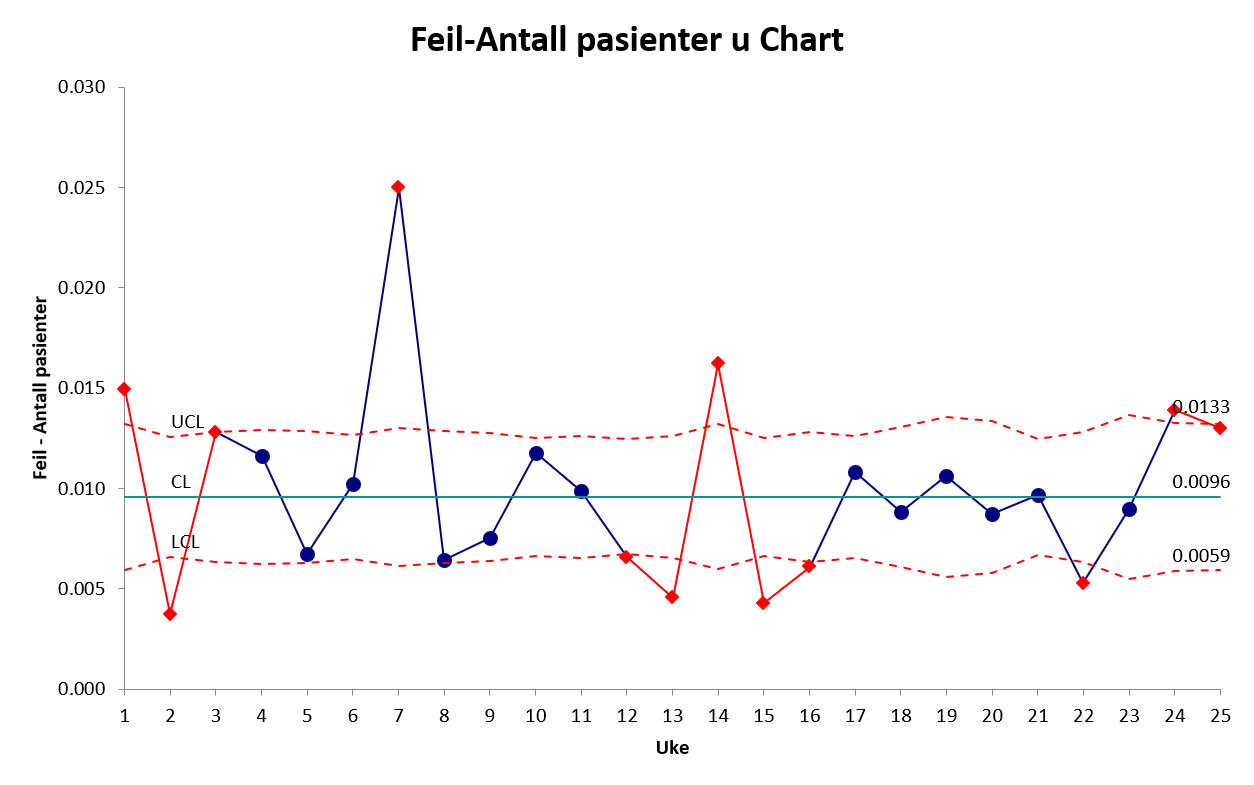
Laneys u-diagram:
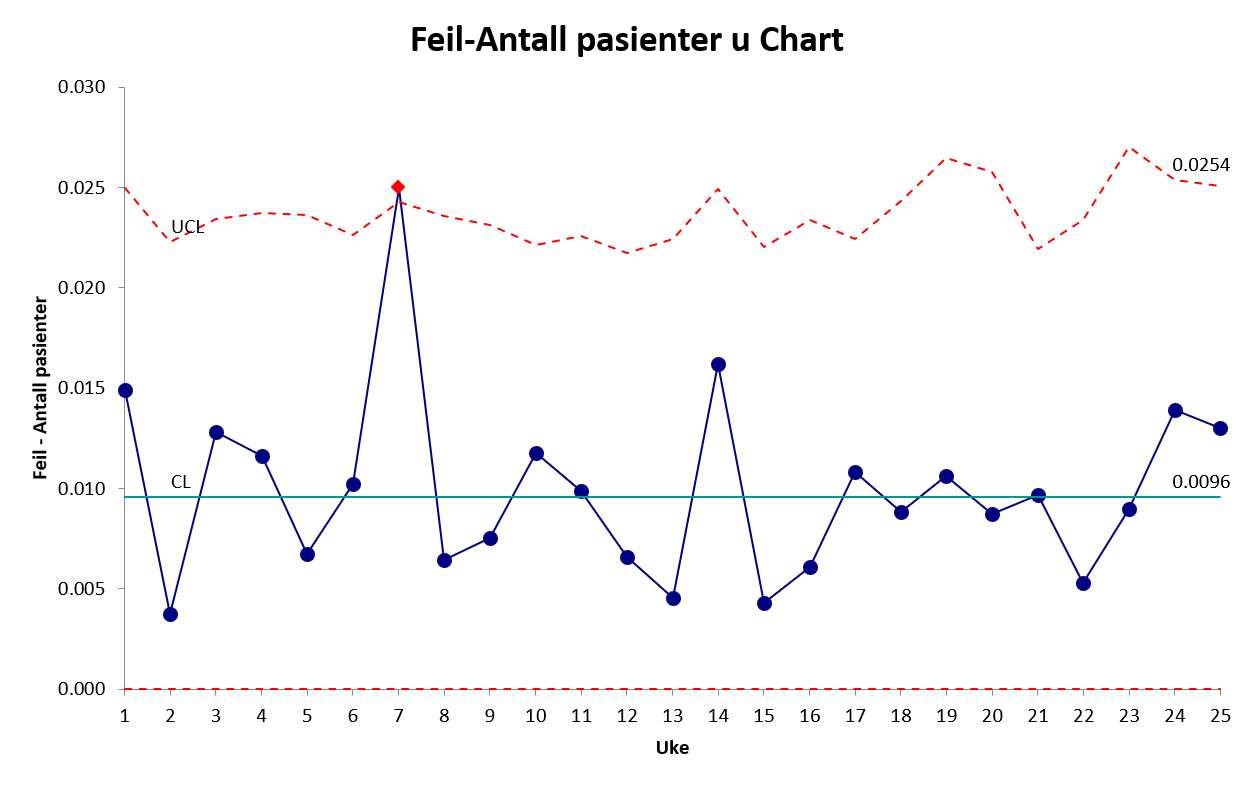 Video som viser frangangsmåte i Excel ligger her
Video som viser frangangsmåte i Excel ligger her
7.3.6 c-diagram
c-diagrammet likner på u-diagrammet, men her er utvalgsstørrelsen lik. Man kan f.eks. registrere antall hendelser med personskader i en fabrikk. Fabrikken vil da utgjøre utvalget og den er lik fra periode til periode.
Vi kan bruke antall feilmedisineringer i en enhet som et eksempel (eksempeldata modifisert fra QIMacros 2021).
Måned | Feilmedisinering | Måned. | Feilmedisinering. |
Jan | 74 | Jan | 75 |
Feb | 70 | Feb | 63 |
Mar | 67 | Mar | 71 |
Apr | 65 | Apr | 59 |
Mai | 63 | Mai | 70 |
Jun | 82 | Jun | 66 |
Jul | 110 | Jul | 97 |
Aug | 61 | Aug | 71 |
Sep | 75 | Sep | 84 |
Okt | 78 | Okt | 85 |
Nov | 76 | Nov | 57 |
Des | 78 | Des | 60 |
Datasett: Download cdiagram.xlsx
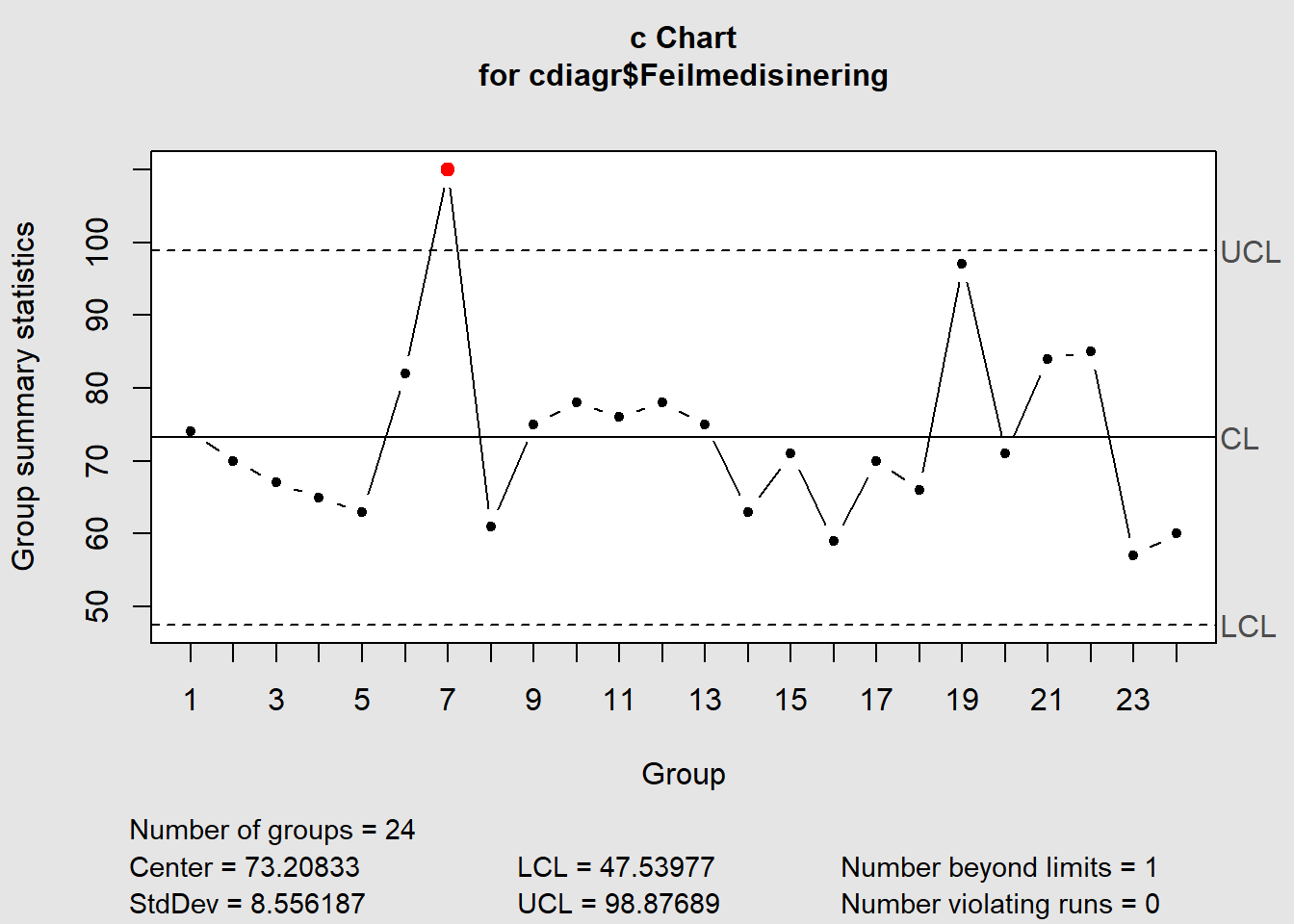
Figure 7.14: c-diagram
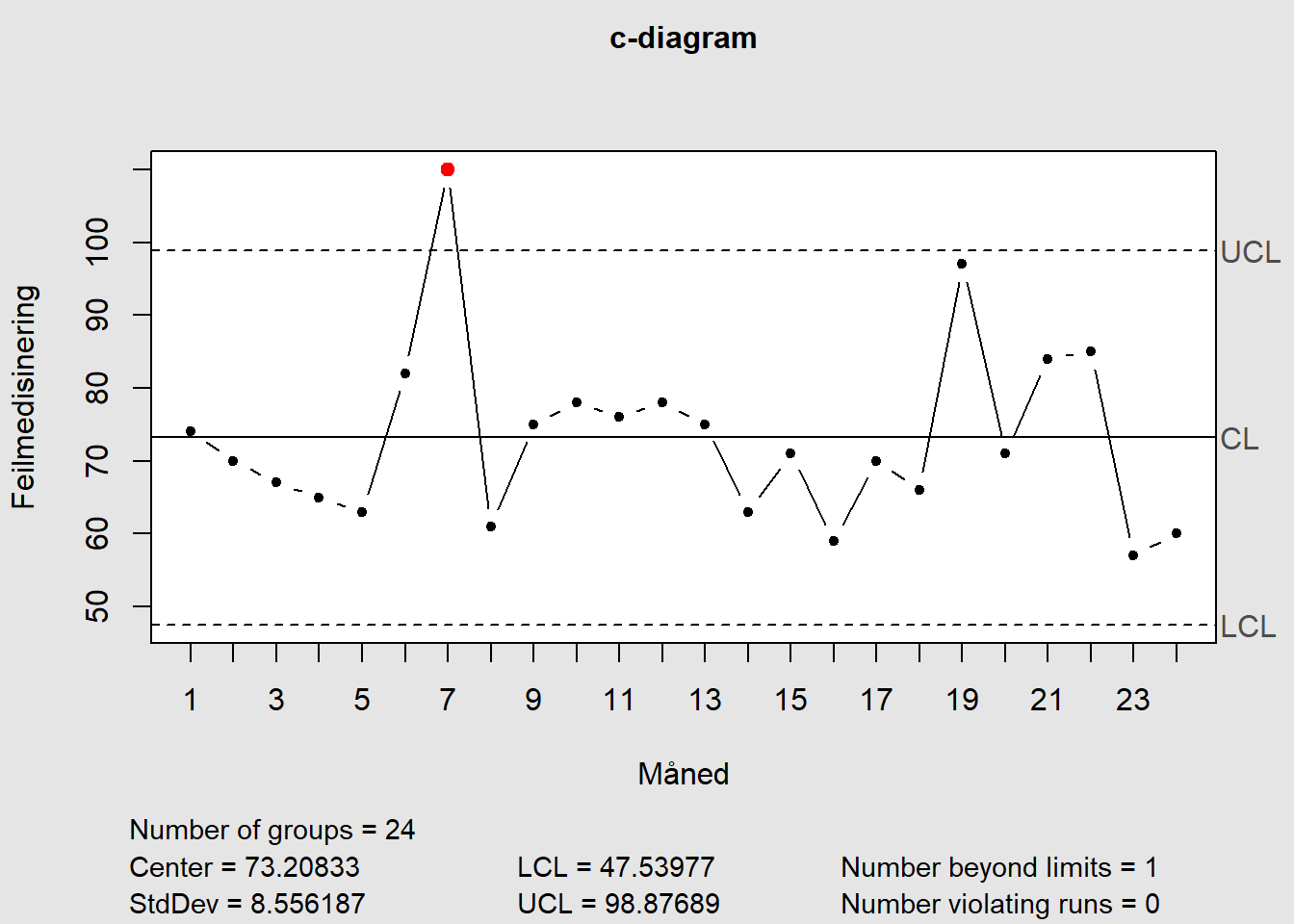
Figure 7.15: c-diagram
Excelvideo her
7.3.7 g-diagram
g-diagrammet brukes på sjeldne hendelser. Her bruker vi dager dager mellom infeksjoner etter en viss type operasjon som eksempel (eksempeldata modifisert fra SPC for Excel 2021).
Dager_mellom |
58 |
22 |
11 |
132 |
6 |
16 |
46 |
9 |
35 |
25 |
67 |
58 |
20 |
11 |
49 |
46 |
57 |
Datasett: Download gdiagram.xlsx
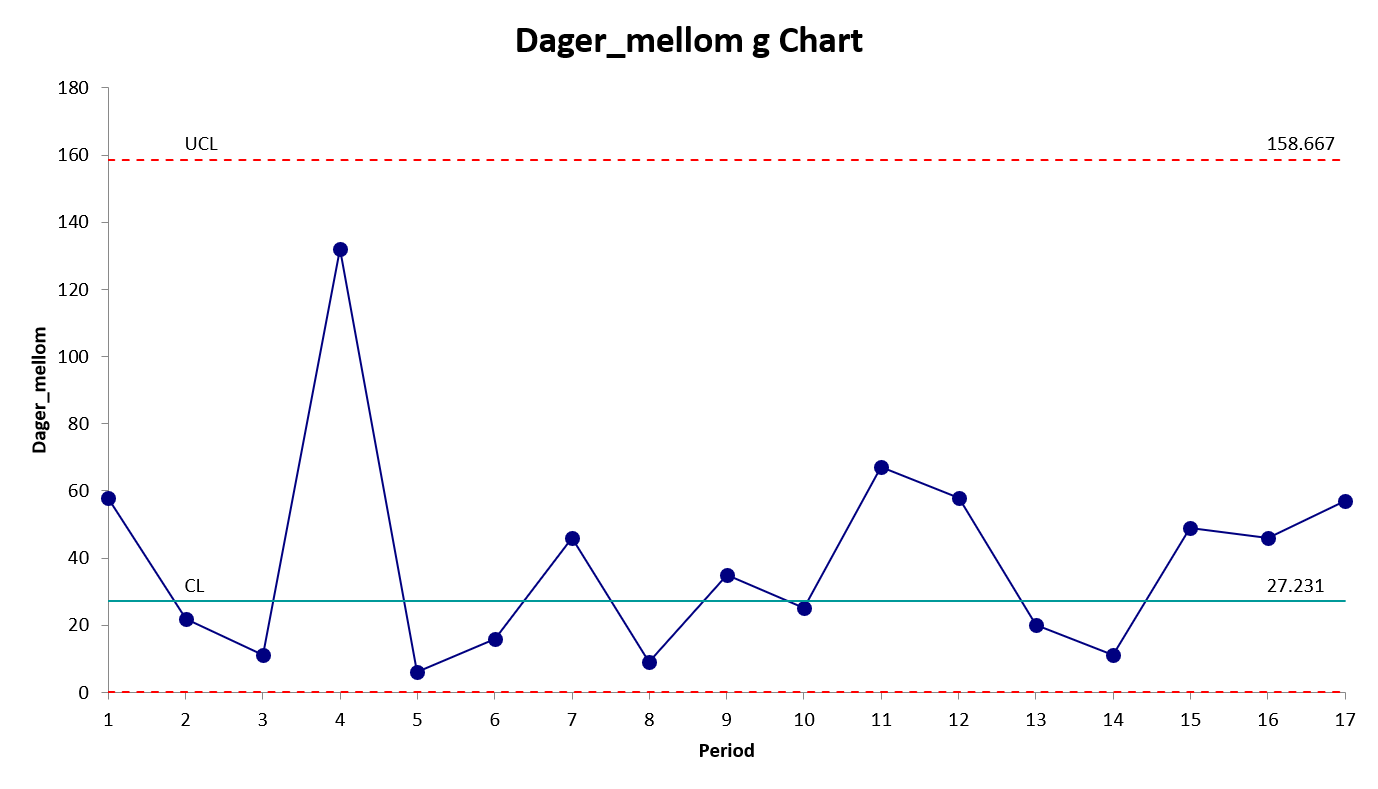 Video for Excel
Video for Excel
I utregning av sentraltendensen oppgis noe ulike utregninger i forskjellige kilder. Noen bruker det aritmetiske gjennomsnittet (slik vi har gjort i de andre diagrammene hittil), mens flertallet ser ut til å bruke en beregnet medianverdi (se Benneyan 2001). Grunnen til dette er at distribusjonen antas å være geometrisk, noe som innebærer at den er betydelig skjevfordelt. Median er dermed en mer representativ verdi for sentraltendensen enn gjennomsnittet. Det legges derfor inn en konstant på 0.693 når man regner ut CL. Samtidig brukes snittet likevel når man regner ut UCL og LCL – framgangsmåten er forklart i videoen.
7.3.8 Utfordringer med telledata og distribusjon på dataene
Alle telledata, om det er antall eller andeler, er individuelle verdier per en eller annen tidsenhet. Som vi kan se av formlene for utregning av UCL og LCL i så vel p som np, u og c utgjør gjennomsnittet grunnlaget for utregning av kontrollgrensene. Dette baserer seg på at dataene følger enten en binomial (for p og np) eller Poisson (for c og u) sannsynlighetsfordeling (jfr kapittelet om datadistribusjon). Som Wheeler (2021) beskriver innebærer det at gjennomsnittet spesifiserer modellen og snittet er grunnlaget for både sentraltendens og spredning/variasjon, men det er uansett en teoretisk tilnærming som baserer seg på at dataene har enten binomial eller Poissonfordeling. Er dataene ikke det viser Wheeler (2021) at kontrollgrensene blir gale, og mange typer telledata har ikke verken binomial eller Poisson fordeling. Man bør derfor kjenne til distribusjonen av telledataene før man benytter p, np, c eller u diagram.
Wheeler (2021) viser at IMR (XMR) diagrammer (se neste delkapittel), som baserer utregningen av kontrollgrensene empirisk (i motsetning til teoretisk ut fra sannsynlighetsfordeling) på Moving Ranges (MR), alltid vil gi deg riktige kontrollgrenser. Kontrollgrensene med et IMR diagram vil således være empirisk utregnet fra den variasjonen du faktisk har i dataene og ikke være teoretisk beregnet ut fra en sannsynlighetsfordeling. Wheelers (2021) artikkel viser gjennom tre eksempler at kontrollgrensen i et IMR-diagram vil replikere de i p, np, c og u der disse er korrekte, og avvike (men vise de riktige) der p, np, c og u viser feil kontrollgrenser. viser at IMR (XMR) diagrammer (se neste delkapittel), som baserer utregningen av kontrollgrensene empirisk (i motsetning til teoretisk ut fra sannsynlighetsfordeling) på Moving Ranges (MR), alltid vil gi deg riktige kontrollgrenser. Kontrollgrensene med et IMR diagram vil således være empirisk utregnet fra den variasjonen du faktisk har i dataene og ikke være teoretisk beregnet ut fra en sannsynlighetsfordeling. Wheeler (2021) artikkel viser gjennom tre eksempler at kontrollgrensen i et IMR-diagram vil replikere de i p, np, c og u der disse er korrekte, og avvike (men vise de riktige) der p, np, c og u viser feil kontrollgrenser.
Som Wheeler (2021) uttrykker det:
In contrast to this use of theoretical models which may or may not be correct, the XmR chart provides us with empirical limits that are actually based upon the variation present in the data. This means that you can use an XmR chart with count-based data anytime you wish. Since the p-chart, the np-chart, the c-chart, and the u-chart are all special cases of the chart for individual values, the XmR chart will mimic these specialty charts when they are appropriate and will differ from them when they are wrong.
Mohammed and Worthington (2012) understreker at så lenge det kun finnes normal variasjon vil kontrollgrensene for IMR(XMR) og p/np/c/u-diagrammer være samsvarende. De peker videre på at dersom det er klare forskjeller mellom IMR og p/np/c/u er det en indikasjon på unormal variasjon. De anbefaler derfor at man bruker begge typene.
Vi foreslår derfor at dersom man ikke er helt sikker på distribusjonen i telledata kan man følge anbefalingen fra Wheeler (2021) anbefaling om å bruke IMR (XMR) diagram. Man kan eventuelt følge anbeflaingen fra Mohammed and Worthington (2012) om å bruke IMR i kombinasjon med p/np/c/u. Man bør trolig være forsiktig med å bruke bare p/np/c/u om man ikke er sikker på distribusjonen.
Under kapittelet om distribusjoner finner du en beskrivelse av ulike aktuelle distribusjoner og hvordan man kan undersøke data med tanke på distribusjon. Et enkelt grep for å få et inntrykk av distribusjonen er et «vanlig» histogram. For dataene brukt i eksempelet over for np-diagram kan vi sammenlikne np-diagrammet med I-diagramdelen av IMR-diagram for samme data:
 Vi kan se det er avvik mellom diagrammene. Np-diagrammet har trangere kontrollgrenser og viser to punkter utenfor øvre kontrollgrense. Hvis vi plotter et Q-Q plott, finner vi:
Vi kan se det er avvik mellom diagrammene. Np-diagrammet har trangere kontrollgrenser og viser to punkter utenfor øvre kontrollgrense. Hvis vi plotter et Q-Q plott, finner vi:
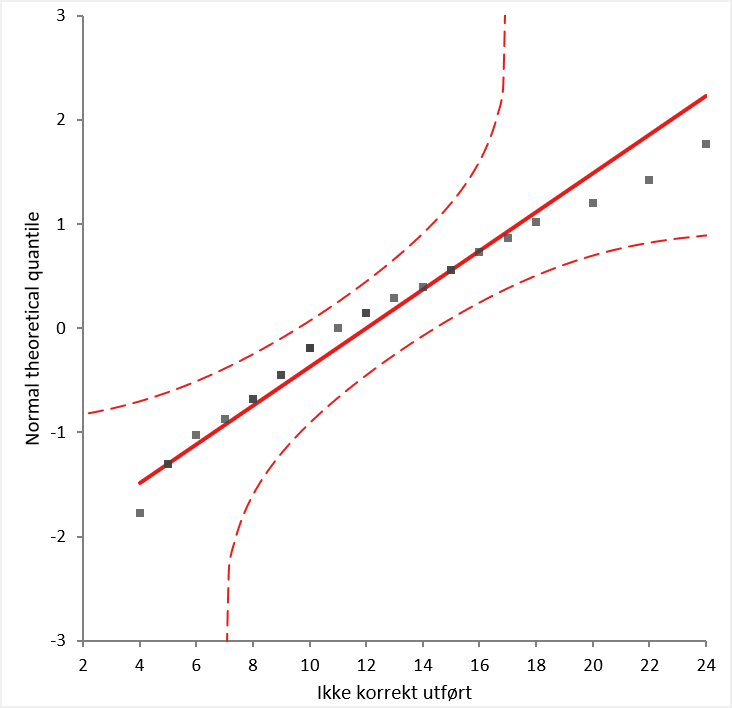
Sammen med statistiske tester for normalitet (Shapiro-Wilk og Anderson-Darling) får vi klare indikasjoner på at datasettet er nærme normalfordeling. Siden et np-diagram bygger på forutsetning om en binomial fordeling virker det mest korrekt å bruke IMR-diagrammet22.
7.4 Måledata (variabler)
7.4.1 IMR (XMR)
Eksempel basert på Anhøj (2021a).
Baby_nr | Fødselsvekt | Baby_nr. | Fødselsvekt. |
1 | 2898 | 13 | 3478 |
3 | 3036 | 14 | 3682 |
3 | 2757 | 15 | 3650 |
4 | 3455 | 16 | 3343 |
5 | 3179 | 17 | 3009 |
6 | 3402 | 18 | 3812 |
7 | 3394 | 19 | 4009 |
8 | 3737 | 20 | 2975 |
9 | 3434 | 21 | 3369 |
10 | 2953 | 22 | 2972 |
11 | 3525 | 23 | 3598 |
12 | 3778 | 24 | 3141 |
Datasett: Download imr_diagram.xlsx
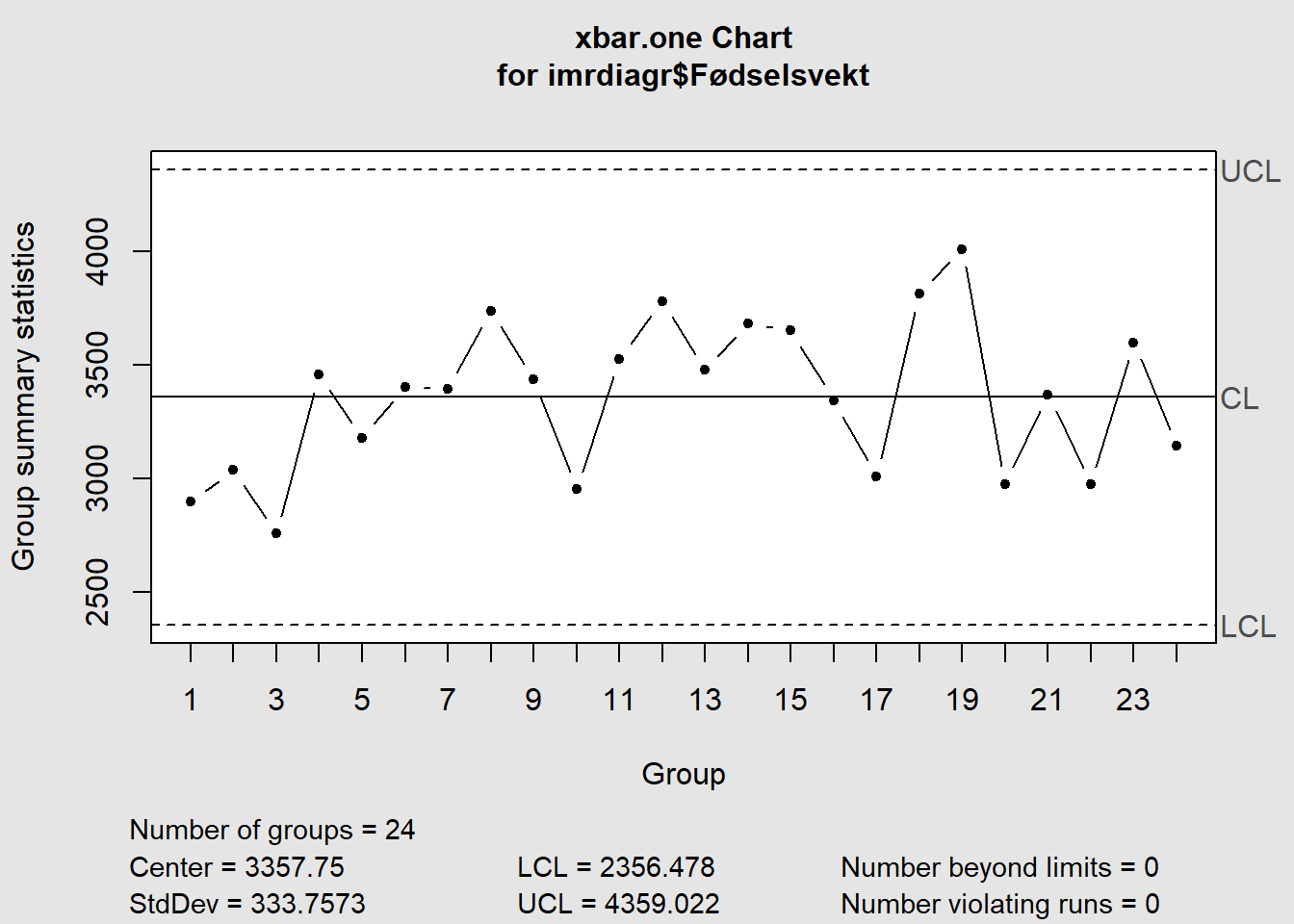
Figure 7.16: IMR-diagram
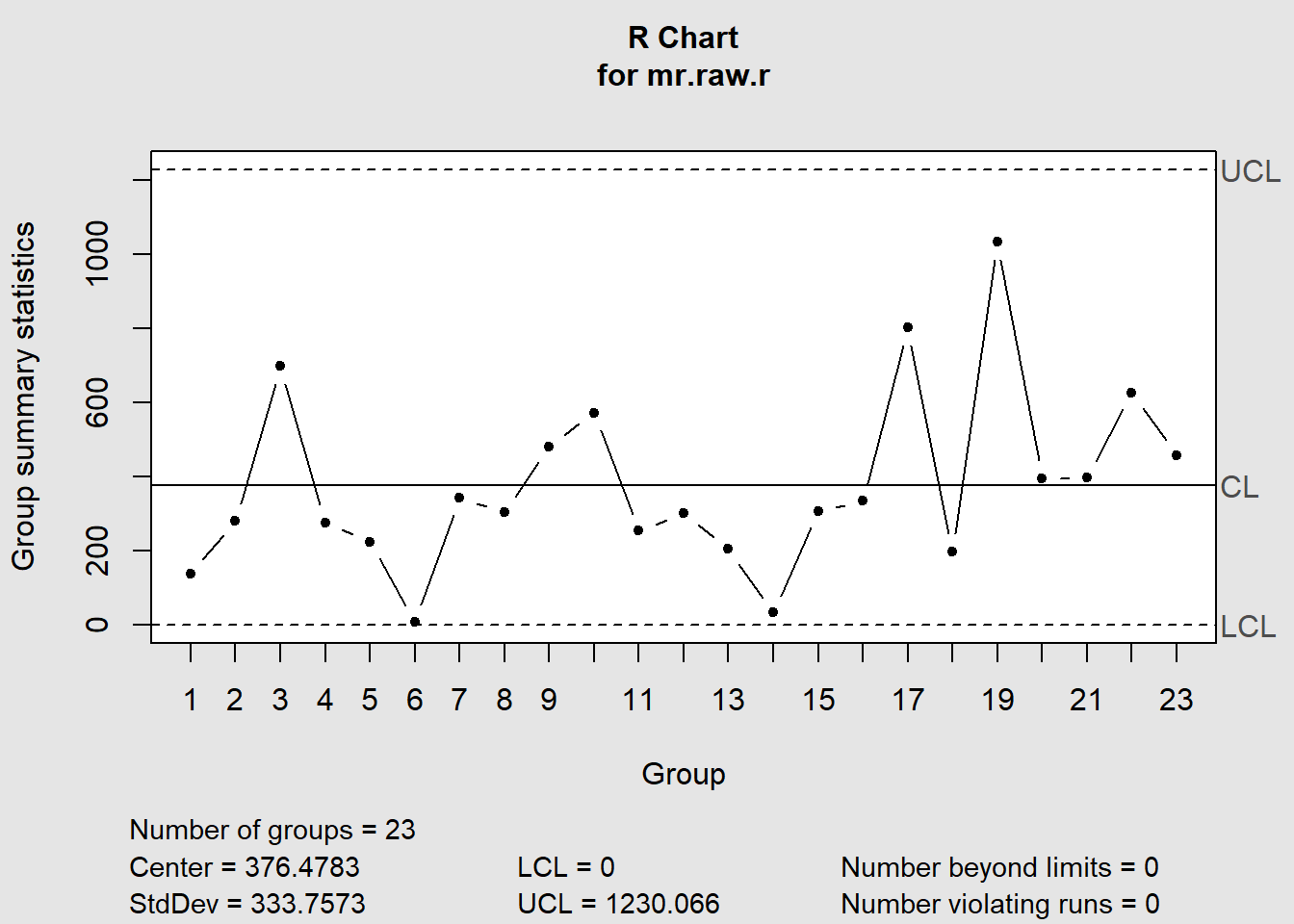
Figure 7.17: IMR-diagram
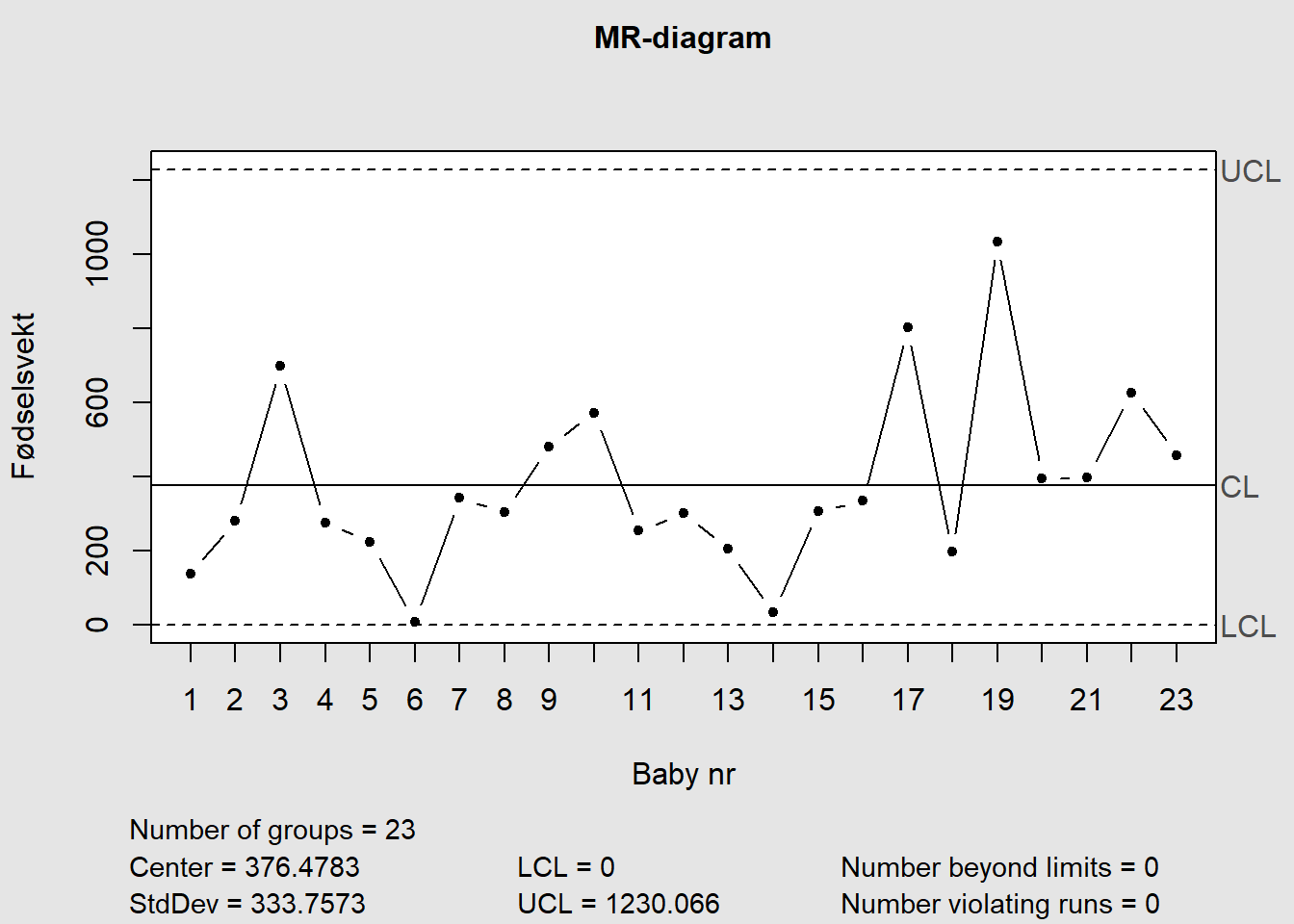
Figure 7.18: IMR-diagram
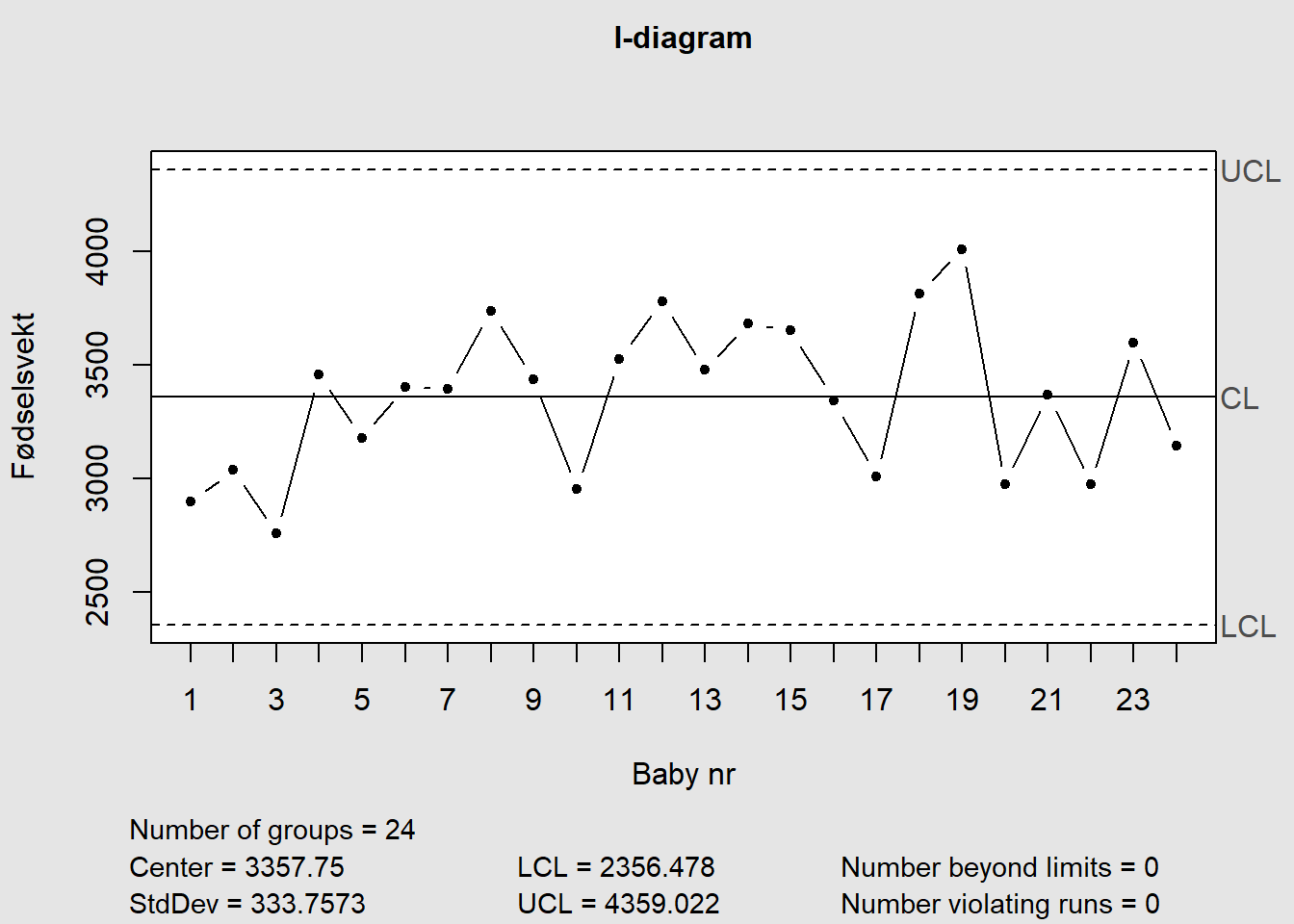
Figure 7.19: IMR-diagram
Framgangsmåte i Excel her
7.4.2 XbarR
Eksempeldata modifisert fra (QIMacros 2021).
Prøve_nr | Obs_1 | Obs_2 | Obs_3 | Obs_4 | Obs_5 |
1 | 74.030 | 74.002 | 74.019 | 73.992 | 74.008 |
3 | 73.995 | 73.992 | 74.001 | 74.011 | 74.004 |
3 | 73.988 | 74.024 | 74.021 | 74.005 | 74.002 |
4 | 74.002 | 73.996 | 73.993 | 74.015 | 74.009 |
5 | 73.992 | 74.007 | 74.015 | 73.989 | 74.014 |
6 | 74.009 | 73.994 | 73.997 | 73.985 | 73.993 |
7 | 73.995 | 74.006 | 73.994 | 74.000 | 74.005 |
8 | 73.985 | 74.003 | 73.993 | 74.015 | 73.988 |
9 | 74.008 | 73.995 | 74.009 | 74.005 | 74.004 |
10 | 73.998 | 74.000 | 73.990 | 74.007 | 73.995 |
11 | 73.994 | 73.998 | 73.994 | 73.995 | 73.990 |
12 | 74.004 | 74.000 | 74.007 | 74.000 | 73.996 |
13 | 73.983 | 74.002 | 73.998 | 73.997 | 74.012 |
14 | 74.006 | 73.967 | 73.994 | 74.000 | 73.984 |
15 | 74.012 | 74.014 | 73.998 | 73.999 | 74.007 |
16 | 74.000 | 73.984 | 74.005 | 73.998 | 73.996 |
17 | 73.994 | 74.012 | 73.986 | 74.005 | 74.007 |
18 | 74.006 | 74.010 | 74.018 | 74.003 | 74.000 |
19 | 73.984 | 74.002 | 74.003 | 74.005 | 73.997 |
20 | 74.000 | 74.010 | 74.013 | 74.020 | 74.003 |
21 | 73.982 | 74.001 | 74.015 | 74.005 | 73.996 |
22 | 74.004 | 73.999 | 73.990 | 74.006 | 74.009 |
23 | 74.010 | 73.989 | 73.990 | 74.009 | 74.014 |
24 | 74.015 | 74.008 | 73.993 | 74.000 | 74.010 |
Datasett: Download XbarR_diagram.xlsx
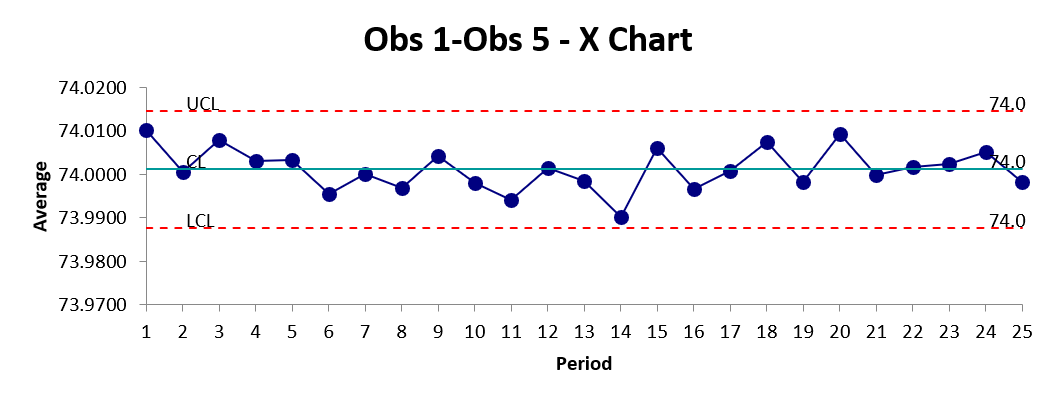 NB NB NB - Lage og sette inn video her.
NB NB NB - Lage og sette inn video her.
7.4.3 XbarS
Eksempeldata modifisert fra (QIMacros 2021). Download XbarS_diagram.xlsx
Måned | Avd1 | Avd2 | Avd3 | Avd4 | Avd5 | Avd6 | Avd7 | Avd8 | Avd9 |
Jan | 25 | 22 | 35 | 23 | 24 | 45 | 36 | 34 | 32 |
Feb | 25 | 22 | 35 | 23 | 24 | 45 | 36 | 34 | 32 |
Mar | 45 | 36 | 34 | 32 | 40 | 35 | 67 | 56 | 34 |
Apr | 34 | 32 | 40 | 35 | 67 | 54 | 57 | 59 | 45 |
Mai | 25 | 22 | 35 | 23 | 24 | 45 | 36 | 34 | 32 |
Jun | 25 | 22 | 35 | 23 | 24 | 45 | 34 | 32 | 40 |
Jul | 45 | 36 | 34 | 32 | 40 | 35 | 67 | 56 | 34 |
Aug | 34 | 32 | 40 | 35 | 67 | 54 | 57 | 59 | 45 |
Sep | 25 | 22 | 35 | 23 | 24 | 45 | 36 | 34 | 32 |
Okt | 25 | 22 | 35 | 23 | 24 | 45 | 36 | 34 | 32 |
Nov | 45 | 36 | 34 | 32 | 40 | 35 | 67 | 56 | 34 |
Des | 34 | 32 | 40 | 35 | 67 | 54 | 57 | 59 | 45 |
Måned | Avd10 | Avd11 | Avd12 | Avd13 | Avd14 | Avd15 | Avd16 | Avd17 | Avd18 | Avd19 |
Jan | 40 | 35 | 67 | |||||||
Feb | 40 | 35 | 67 | 25 | 22 | 35 | 23 | 24 | 45 | 36 |
Mar | 55 | 67 | 44 | 68 | 46 | 45 | ||||
Apr | 44 | 67 | 47 | 53 | 55 | 43 | 22 | 67 | ||
Mai | 40 | 35 | 67 | |||||||
Jun | 35 | 67 | 25 | 22 | 35 | 23 | 24 | 45 | 36 | |
Jul | 55 | 67 | 44 | 68 | 46 | 45 | ||||
Aug | 44 | 67 | 47 | 53 | 55 | 43 | 22 | 67 | ||
Sep | 40 | 35 | 67 | |||||||
Okt | 40 | 35 | 67 | 25 | 22 | 35 | 23 | 24 | 45 | 36 |
Nov | 55 | 67 | 44 | 68 | 46 | 45 | ||||
Des | 44 | 67 | 47 | 53 | 55 | 43 | 22 | 67 |
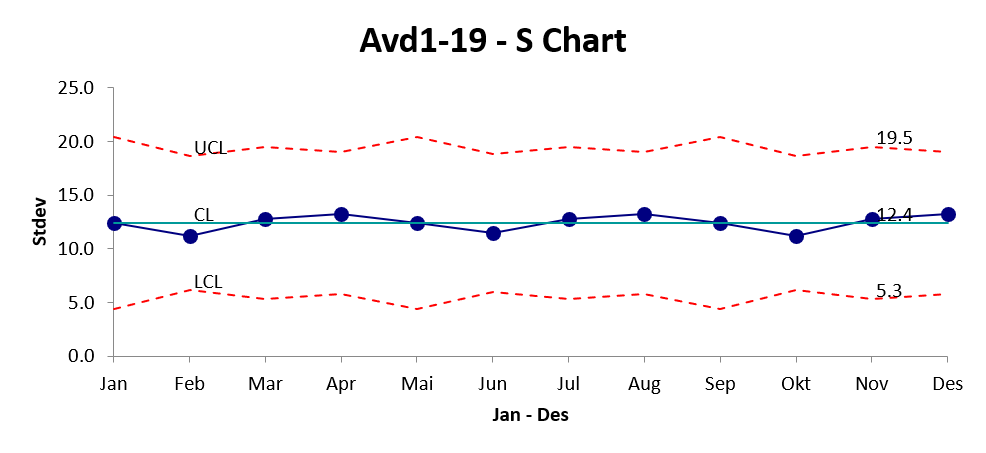
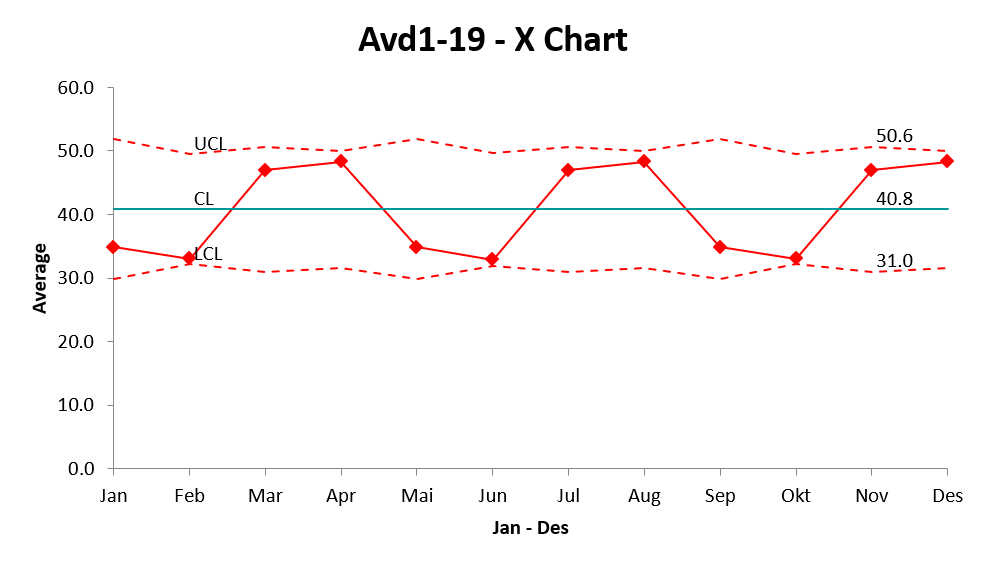
Video kommer her
7.4.4 T-diagram
I likhet med g-diagrammet er T-diagrammet er diagram vi kan bruke når det er lang tid mellom hendelser (sjeldne hendelser). I g-diagrammet så vi på antall tilfeller mellom hver uønskede hendelse. T-diagrammet brukes når vi vil se på tid mellom hendelser. Siden antall tilfeller mellom hendelser er en diskret variabel og tid er en kontinuerlig variabel plasseres de hhv. i “telledata” og “måledata”.
Eksempelet under er modifisert fra Anhøj (2021a).
Datasett: Download t_diagram_data.xlsx
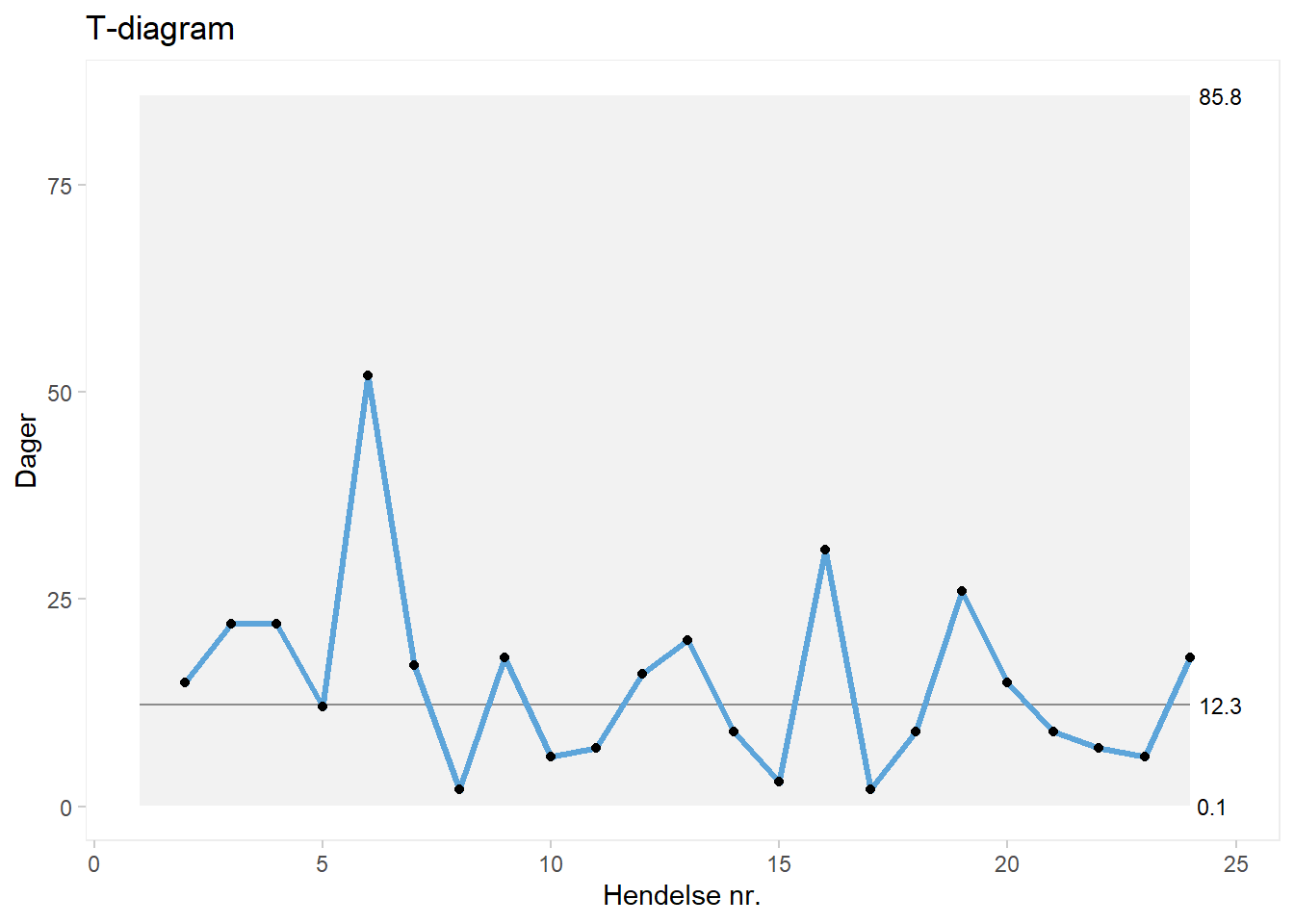
Figure 7.20: t-diagram
Video kommer her